

Configuring the Director
Of all the configuration files needed to run Bacula, the Director's is the most complicated, and the one that you will need to modify the most often as you add clients or modify the FileSets.
For a general discussion of configuration files and resources including the data types recognized by Bacula, please see the Configuration chapter of this manual.
Director Resource Types
Director resource types may be the following:
Job, JobDefs, Client, Storage/Autochanger, Catalog, Schedule, FileSet, Pool, Director, Console, Counter, and Messages. We present them here in the most logical order for defining them.
Note, everything revolves around a job and is tied to a job in one way or another.
- Director - to define the Director's name and its access password used for authenticating the Console program. Only a single Director resource definition may appear in the Director's configuration file. If you have either /dev/random or bc on your machine, Bacula will generate a random password during the configuration process, otherwise it will be left blank.
- Job - to define the backup/restore Jobs and to tie together the Client, FileSet and Schedule resources to be used for each Job. Normally, you will have Jobs of different names corresponding to each client (i.e., one Job per client, but a different one with a different name for each client).
- JobDefs - optional resource for providing defaults for Job resources.
- Schedule - to define when a Job is to be automatically run by Bacula's internal scheduler. You may have any number of Schedules, but each job will reference only one.
- FileSet - to define the set of files to be backed up with each job. You may have any number of FileSets but each Job will reference only one.
- Client - to define what Client is to be backed up. You will generally have multiple Client definitions. Each Job will reference only a single client.
- Storage (or Autochanger) - to define on what physical device the Volumes should be mounted. You may have one or more Storage definitions.
- Pool - to define the pool of Volumes that can be used for a particular Job.If there is a large number of clients or volumes, you may want to have multiple Pools. Pools allow you to restrict a Job (or a Client) to use only a particular set of Volumes.
- Catalog - to define in what database to keep the list of files and the Volume names where they are backed up. Most people only use a single catalog. However, if you want to scale the Director to many clients, multiple catalogs can be helpful. Multiple catalogs require a bit more management because in general you must know what catalog contains what data. Currently, all Pools are defined in each catalog. This restriction will be removed in a later release.
- Console - to define how the administrator or user can interact with the Director.
- Counter - to define a counter variable that can be accessed by variable expansion used for creating Volume labels.
- Messages - to define where error and information messages are to be sent or logged. You may define multiple different message resources and hence direct particular classes of messages to different users or locations (files, ...).
The Director Resource
The Director resource defines the attributes of the Directors running on the network. In the current implementation, there is only a single Director resource, but a future design may contain multiple Directors to maintain index and media database redundancy.
- Director
- Start of the Director resource. One and only one director resource must be supplied.
- Name = <name>
- The director name used by the system administrator. This directive is required.
- Description = <text>
- The text field contains a description of the Director that will be displayed in the graphical user interface. This directive is optional.
- Password = <UA-password>
- Specifies the password that must be supplied for the default Bacula Console to be authorized. The same password must appear in the Director resource of the Console configuration file. For added security, the password is never passed across the network but instead a challenge response hash code created from the password. This directive is required. If you have either /dev/random or bc on your machine, Bacula will generate a random password during the configuration process, otherwise it will be left blank and you must manually supply it.
The password is plain text. It is not generated through any special process but as noted above, it is better to use random text for security reasons.
- Messages = <Messages-resource-name>
- The messages resource specifies where to deliver Director messages that are not associated with a specific Job. Most messages are specific to a job and will be directed to the Messages resource specified by the job. However, there are a few messages that can occur when no job is running. This directive is required.
- Working Directory = <Directory>
- This directive is mandatory and specifies a directory in which the Director may put its status files. This directory should be used only by Bacula but may be shared by other Bacula daemons. However, please note, if this directory is shared with other Bacula daemons (the File daemon and Storage daemon), you must ensure that the Name given to each daemon is unique so that the temporary filenames used do not collide. By default the Bacula configure process creates unique daemon names by postfixing them with -dir, -fd, and -sd. Standard shell expansion of the Working Directory is done when the configuration file is read so that values such as $HOME will be properly expanded. This directive is required.
The working directory specified must already exist and be readable and writable by the Bacula daemon referencing it.
If you have specified a Director user and/or a Director group on your ./configure line with -with-dir-user and/or -with-dir-group the Working Directory owner and group will be set to those values.
- Pid Directory = <Directory>
- This directive is mandatory and specifies a directory in which the Director may put its process Id file. The process Id file is used to shutdown Bacula and to prevent multiple copies of Bacula from running simultaneously. Standard shell expansion of the Pid Directory is done when the configuration file is read so that values such as $HOME will be properly expanded.
The PID directory specified must already exist and be readable and writable by the Bacula daemon referencing it
Typically on Linux systems, you will set this to: /var/run. If you are not installing Bacula in the system directories, you can use the Working Directory as defined above. This directive is required.
- Scripts Directory = <Directory>
- This directive is optional and, if defined, specifies a directory in which the Director and the Storage daemon will look for many of the scripts that it needs to use during particular operations such as starting/stopping, the mtx-changer script, tape alerts, as well as catalog updates. This directory may be shared by other Bacula daemons. Standard shell expansion of the directory is done when the configuration file is read so that values such as $HOME will be properly expanded.
- QueryFile = <Path>
- This directive is mandatory and specifies a directory and file in which the Director can find the canned SQL statements for the query command of the Console. Standard shell expansion of the <Path> is done when the configuration file is read so that values such as $HOME will be properly expanded. This directive is required.
- Heartbeat Interval = <time-interval>
- This directive is optional and if specified will cause the Director to set a keepalive interval (heartbeat) in seconds on each of the sockets it opens for the Client resource. This value will override any specified at the Director level. It is implemented only on systems (Linux, ...) that provide the setsockopt TCP_KEEPIDLE function. The default value is 300s.
- Maximum Concurrent Jobs = <number>
- where <number> is the maximum number of total Director Jobs that should run concurrently. The default is set to 20, but you may set it to a larger number. Every valid connection to any daemon (Director, File daemon, or Storage daemon) results in a Job. This includes connections from Bacula Console. Thus the number of concurrent Jobs must, in general, be greater than the maximum number of Jobs that you wish to actually run.
In general, increasing the number of Concurrent Jobs increases the total throughtput of Bacula, because the simultaneous Jobs can all feed data to the Storage daemon and to the Catalog at the same time. However, keep in mind, that the Volume format becomes more complicated with multiple simultaneous jobs, consequently, restores may take longer if Bacula must sort through interleaved volume blocks from multiple simultaneous jobs. Though not normally necessary, this can be avoided by having each simultaneous job write to a different volume or by using data spooling, which will first spool the data to disk simultaneously, then write one spool file at a time to the volume thus avoiding excessive interleaving of the different job blocks.
- FD Connect Timeout = <time>
- where <time> is the time that the Director should continue attempting to contact the File daemon to start a job, and after which the Director will cancel the job. The default is 3 minutes.
- SD Connect Timeout = <time>
- where <time> is the time that the Director should continue attempting to contact the Storage daemon to start a job, and after which the Director will cancel the job. The default is 30 minutes.
- DirAddresses = <IP-address-specification>
- Specify the ports and addresses on which the Director daemon will listen for Bacula Console connections. Probably the simplest way to explain this is to show an example:
DirAddresses = { ip = { addr = 1.2.3.4; port = 1205;} ipv4 = { addr = 1.2.3.4; port = http; } ipv6 = { addr = 1.2.3.4; port = 1205; } ip = { addr = 1.2.3.4 port = 1205 } ip = { addr = 1.2.3.4 } ip = { addr = 201:220:222::2 } ip = { addr = bluedot.thun.net } }where ip, ip4, ip6, addr, and port are all keywords. Note, that the address can be specified as either a dotted quadruple, or IPv6 colon notation, or as a symbolic name (only in the ip specification). Also, port can be specified as a number or as the mnemonic value from the /etc/services file. If a port is not specified, the default will be used. If an ip section is specified, the resolution can be made either by IPv4 or IPv6. If ip4 is specified, then only IPv4 resolutions will be permitted, and likewise with ip6.
Please note that if you use the DirAddresses directive, you must not use either a DirPort or a DirAddress directive in the same resource.
- DirPort = <port-number>
- Specify the port (a positive integer) on which the Director daemon will listen for Bacula Console connections. This same port number must be specified in the Director resource of the Console configuration file. The default is 9101, so normally this directive need not be specified. This directive should not be used if you specify the DirAddresses (plural) directive.
- DirAddress = <IP-Address>
- This directive is optional, but if it is specified, it will cause the Director server (for the Console program) to bind to the specified <IP-Address>, which is either a domain name or an IP address specified as a dotted quadruple in string or quoted string format. If this directive is not specified, the Director will bind to any available address (the default). Note, unlike the DirAddresses specification noted above, this directive only permits a single address to be specified. This directive should not be used if you specify a DirAddresses (plural) directive.
- DirSourceAddress = <IP-Address>
- This record is optional, and if it is specified, it will cause the Director server (when initiating connections to a storage or file daemon) to source its connections from the specified address. Only a single IP address may be specified. If this record is not specified, the Director server will source its outgoing connections according to the system routing table (the default).
- Events Retention = <time>
-
The Events Retention directive defines the length of time that Bacula will keep events records in the Catalog database. When this time period expires, and if the user runs the prune events command, Bacula will prune (remove) Events records that are older than the specified period.
See the Configuration chapter of this manual for additional details of time specifications.
The default is 1 month.
- Statistics Retention = <time>
-
The Statistics Retention directive defines the length of time that Bacula will keep statistics job records in the Catalog database after the Job End time. (In JobHistory table) When this time period expires, and if the user runs the prune stats command, Bacula will prune (remove) Job records that are older than the specified period.
Theses statistics records aren't used for restore purpose, but mainly for capacity planning, billings, etc. See Statistics chapter for additional information.
See the Configuration chapter of this manual for additional details of time specifications.
- AutoPrune = <yes|no>
-
Normally, pruning of Files from the Catalog is specified on a Client by Client basis in the Client resource with the AutoPrune directive. It is also possible to overwrite the Client settings in the Pool resource used by jobs, with the AutoPrune, PruneFiles and PruneJobs directives.
If this directive is specified (not normally) and the value is no, it will override the value specified in all the Client and the Pool resources. The default is yes.
If you set AutoPrune = no, pruning will not be done automatically, and your Catalog will grow in size each time you run a Job. Pruning affects only information in the catalog and not data stored in the backup archives (on Volumes). The prune bconsole command can be used to prune catalog records respecting the Client and/or the Pool FileRetention, JobRetention and VolumeRetention directives.
- VerId = <string>
- where <string> is an identifier which can be used for support purpose. This string is displayed using the version command.
- MaximumConsoleConnections = <number>
- where <number> is the maximum number of Console Connections that could run concurrently. The default is set to 20, but you may set it to a larger number.
- MaximumReloadRequests = <number>
-
Where <number> is the maximum number of reload command that can be queued while jobs are running. The default is set to 32 and is usually sufficient.
- CommCompression = <yes|no>
-
If the two Bacula components (DIR, FD, SD, bconsole) have the comm line compression enabled, the line compression will be enabled. The default value is yes.
In many cases, the volume of data transmitted across the communications line can be reduced by a factor of three when this directive is enabled. In the case that the compression is not effective, Bacula turns it off on a record by record basis.
If you are backing up data that is already compressed the comm line compression will not be effective, and you are likely to end up with an average compression ratio that is very small. In this case, Bacula reports None in the Job report.
- TLS Enable = <yes|no>
-
Enable TLS support. If TLS is not enabled, none of the other TLS directives have any effect. In other words, even if you set TLS Require = yes you need to have TLS enabled or TLS will not be used.
- TLS PSK Enable = <yes|no>
-
Enable or Disable automatic TLS PSK support. TLS PSK is enabled by default between all Bacula components. The Pre-Shared Key used between the programs is the Bacula password. If both TLS Enable and TLS PSK Enable are enabled, the system will use TLS certificates.
- TLS Require = <yes|no>
-
Require TLS or TLS-PSK encryption. This directive is ignored unless one of TLS Enable or TLS PSK Enable is set to yes. If TLS is not required while TLS or TLS-PSK are enabled, then the Bacula component will connect with other components either with or without TLS or TLS-PSK
If TLS or TLS-PSK is enabled and TLS is required, then the Bacula component will refuse any connection request that does not use TLS.
- TLS Authenticate = <yes|no>
- When TLS Authenticate is enabled, after doing the CRAM-MD5 authentication, Bacula will also do TLS authentication, then TLS encryption will be turned off, and the rest of the communication between the two Bacula components will be done without encryption. If TLS-PSK is used instead of the regular TLS, the encryption is turned off after the TLS-PSK authentication step.
If you want to encrypt communications data, use the normal TLS directives but do not turn on TLS Authenticate.
- TLS Certificate = <Filename>
- The full path and filename of a PEM encoded TLS certificate. It will be used as either a client or server certificate, depending on the connection direction. PEM stands for Privacy Enhanced Mail, but in this context refers to how the certificates are encoded. This format is used because PEM files are base64 encoded and hence ASCII text based rather than binary. They may also contain encrypted information.
This directive is required in a server context, but it may not be specified in a client context if TLS Verify Peer is set to no in the corresponding server context.
Example:
File Daemon configuration file (bacula-fd.conf), Director resource configuration has TLS Verify Peer = no:
Director { Name = bacula-dir Password = "password" Address = director.example.com # TLS configuration directives TLS Enable = yes TLS Require = yes TLS Verify Peer = no TLS CA Certificate File = /opt/bacula/ssl/certs/root_cert.pem TLS Certificate = /opt/bacula/ssl/certs/client1_cert.pem TLS Key = /opt/bacula/ssl/keys/client1_key.pem }Having TLS Verify Peer = no, means the File Daemon, server context, will not check Directorâs public certificate, client context. There is no need to specify TLS Certificate File neither TLS Key directives in the Client resource, director configuration file. We can have the below client configuration in bacula-dir.conf:
Client { Name = client1-fd Address = client1.example.com FDPort = 9102 Catalog = MyCatalog Password = "password" ... # TLS configuration directives TLS Enable = yes TLS Require = yes TLS CA Certificate File = /opt/bacula/ssl/certs/ca_client1_cert.pem } - TLS Key = <Filename>
- The full path and filename of a PEM encoded TLS private key. It must correspond to the TLS certificate.
- TLS Verify Peer = <yes|no>
- Verify peer certificate. Instructs server to request and verify the client's X.509 certificate. Any client certificate signed by a known-CA will be accepted. Additionally, the client's X509 certificate Common Name must meet the value of the Address directive. If the TLSAllowed CN onfiguration directive is used, the client's x509 certificate Common Name must also correspond to one of the CN specified in the TLS Allowed CN directive. This directive is valid only for a server and not in client context. The default is yes.
- TLS Allowed CN = <string list>
- Common name attribute of allowed peer certificates. This directive is valid for a server and in a client context. If this directive is specified, the peer certificate will be verified against this list. In the case this directive is configured on a server side, the allowed CN list will not be checked if TLS Verify Peer is set to no (TLS Verify Peer is yes by default). This can be used to ensure that only the CN-approved component may connect. This directive may be specified more than once.
In the case this directive is configured in a server side, the allowed CN list will only be checked if TLS Verify Peer = yes (default). For example, in bacula-fd.conf, Director resource definition:
Director { Name = bacula-dir Password = "password" Address = director.example.com # TLS configuration directives TLS Enable = yes TLS Require = yes # if TLS Verify Peer = no, then TLS Allowed CN will not be checked. TLS Verify Peer = yes TLS Allowed CN = director.example.com TLS CA Certificate File = /opt/bacula/ssl/certs/root_cert.pem TLS Certificate = /opt/bacula/ssl/certs/client1_cert.pem TLS Key = /opt/bacula/ssl/keys/client1_key.pem }In the case this directive is configured in a client side, the allowed CN list will always be checked.
Client { Name = client1-fd Address = client1.example.com FDPort = 9102 Catalog = MyCatalog Password = "password" ... # TLS configuration directives TLS Enable = yes TLS Require = yes # the Allowed CN will be checked for this client by director # the client's certificate Common Name must match any of # the values of the Allowed CN list TLS Allowed CN = client1.example.com TLS CA Certificate File = /opt/bacula/ssl/certs/ca_client1_cert.pem TLS Certificate = /opt/bacula/ssl/certs/director_cert.pem TLS Key = /opt/bacula/ssl/keys/director_key.pem }If the client doesnât provide a certificate with a Common Name that meets any value in the TLS Allowed CN list, an error message will be issued:
16-Nov 17:30 bacula-dir JobId 0: Fatal error: bnet.c:273 TLS certificate verification failed. Peer certificate did not match a required commonName 16-Nov 17:30 bacula-dir JobId 0: Fatal error: TLS negotiation failed with FD at "192.168.100.2:9102".
- TLS CA Certificate File = <Filename>
- The full path and filename specifying a PEM encoded TLS CA certificate(s). Multiple certificates are permitted in the file. One of TLS CA Certificate File or TLS CA Certificate Dir are required in a server context, unless TLS Verify Peer (see above) is set to no, and are always required in a client context.
- TLS CA Certificate Dir = <Directory>
- Full path to TLS CA certificate directory. In the current implementation, certificates must be stored PEM encoded with OpenSSL-compatible hashes, which is the subject name's hash and an extension of .0. One of TLS CA Certificate File or TLS CA Certificate Dir are required in a server context, unless TLS Verify Peer is set to no, and are always required in a client context.
- TLS DH File = <Directory>
- Path to PEM encoded Diffie-Hellman parameter file. If this directive is specified, DH key exchange will be used for the ephemeral keying, allowing for forward secrecy of communications. DH key exchange adds an additional level of security because the key used for encryption/decryption by the server and the client is computed on each end and thus is never passed over the network if Diffie-Hellman key exchange is used. Even if DH key exchange is not used, the encryption/decryption key is always passed encrypted. This directive is only valid within a server context.
To generate the parameter file, you may use openssl:
openssl dhparam -out dh4096.pem -5 4096
The following is an example of a valid Director resource definition:
Director {
Name = HeadMan
WorkingDirectory = "$HOME/bacula/bin/working"
Password = UA_password
PidDirectory = "$HOME/bacula/bin/working"
QueryFile = "$HOME/bacula/bin/query.sql"
Messages = Standard
}
The Job Resource
The Job resource defines a Job (Backup, Restore, ...) that Bacula must perform. Each Job resource definition contains the name of a Client and a FileSet to backup, the Schedule for the Job, where the data are to be stored, and what media Pool can be used. In effect, each Job resource must specify What, Where, How, and When or FileSet, Storage, Backup/Restore/Level, and Schedule respectively. Note, the FileSet must be specified for a restore job for historical reasons, but it is no longer used.
Only a single type (Backup, Restore, ...) can be specified for any job. If you want to backup multiple FileSets on the same Client or multiple Clients, you must define a Job for each one.
Note, you define only a single Job to do the Full, Differential, and Incremental backups since the different backup levels are tied together by a unique Job name. Normally, you will have only one Job per Client, but if a client has a really huge number of files (more than several million), you might want to split it into to Jobs each with a different FileSet covering only part of the total files.
Multiple Storage daemons are not currently supported for Jobs, so if you do want to use multiple storage daemons, you will need to create a different Job and ensure that for each Job that the combination of Client and FileSet are unique. The Client and FileSet are what Bacula uses to restore a client, so if there are multiple Jobs with the same Client and FileSet or multiple Storage daemons that are used, the restore will not work. This problem can be resolved by defining multiple FileSet definitions (the names must be different, but the contents of the FileSets may be the same).
- Job
- Start of the Job resource. At least one Job resource is required.
- Name = <name>
- The Job name. This name can be specified on the run command in the console program to start a job. If the name contains spaces, it must be specified between quotes. It is generally a good idea to give your job the same name as the Client that it will backup. This permits easy identification of jobs.
When the job actually runs, the unique Job Name will consist of the name you specify here followed by the date and time the job was scheduled for execution. This directive is required.
- Enabled = <yes|no>
- This directive allows you to enable or disable a Job resource. When the resource of the Job is disabled, the Job will no longer be scheduled and it will not be available in the list of Jobs to be run. To be able to use the Job you must enable it.
- Tag = <string, string2, string3>
- The Tag directive specifies a list of tags to create when creating a new Job record. This directive is optional.
- Type = <job-type>
- The Type directive specifies the Job type, which may be one of the following: Backup, Restore, Verify, or Admin. This directive is required. Within a particular Job Type, there are also Levels as discussed in the next item.
- Backup
- Run a backup Job. Normally you will have at least one Backup job for each client you want to save. Normally, unless you turn off cataloging, most all the important statistics and data concerning files backed up will be placed in the catalog.
- Restore
- Run a restore Job. Normally, you will specify only one Restore job which acts as a sort of prototype that you will modify using the console program in order to perform restores. Although certain basic information from a Restore job is saved in the catalog, it is very minimal compared to the information stored for a Backup job - for example, no File database entries are generated since no Files are saved.
Restore jobs cannot be automatically started by the scheduler as is the case for Backup, Verify and Admin jobs. To restore files, you must use the restore command in the console.
- Verify
- Run a Verify Job. In general, Verify jobs permit you to compare the contents of the catalog to the file system, or to what was backed up. In addition, to verifying that a tape that was written can be read, you can also use Verify as a sort of tripwire intrusion detection.
- Admin
Run an Admin Job. Only Director's runscripts will be executed. The Client is not involved in an Admin job, so features such as Client Run Before Job are not available. Although an Admin job is recorded in the catalog, very little data is saved. An Admin job can be used to periodically run catalog pruning, if you do not want to do it at the end of each Backup Job.
- Migration
- Run a Migration Job (similar to a backup job) that reads data that was previously backed up to a Volume and writes it to another Volume. (See (here))
- Copy
- Run a Copy Job that essentially creates two identical copies of the same backup. The Copy process is essentially identical to the Migration feature with the exception that the Job that is copied is left unchanged. (See (here))
- Level = <job-level>
- The Level directive specifies the default Job level to be run. Each different Job Type (Backup, Restore, ...) has a different set of Levels that can be specified. The Level is normally overridden by a different value that is specified in the Schedule resource. This directive is not required, but must be specified either by a Level directive or as an override specified in the Schedule resource.
For a Backup Job, the Level may be one of the following:
- Full
- When the Level is set to Full all files in the FileSet whether or not they have changed will be backed up.
- Incremental
- When the Level is set to Incremental all files specified in the FileSet that have changed since the last successful backup of the the same Job using the same FileSet and Client, will be backed up. If the Director cannot find a previous valid Full backup then the job will be upgraded into a Full backup. When the Director looks for a valid backup record in the catalog database, it looks for a previous Job with:
- The same Job name.
- The same Client name.
- The same FileSet (any change to the definition of the FileSet such as adding or deleting a file in the Include or Exclude sections constitutes a different FileSet.
- The Job was a Full, Differential, or Incremental backup.
- The Job terminated normally (i.e. did not fail or was not canceled).
- The Job started no longer ago than Max Full Interval.
If all the above conditions do not hold, the Director will upgrade the Incremental to a Full save. Otherwise, the Incremental backup will be performed as requested.
The File daemon (Client) decides which files to backup for an Incremental backup by comparing start time of the prior Job (Full, Differential, or Incremental) against the time each file was last “modified” (st_mtime) and the time its attributes were last “changed”(st_ctime). If the file was modified or its attributes changed on or after this start time, it will then be backed up.
Some virus scanning software may change st_ctime while doing the scan. For example, if the virus scanning program attempts to reset the access time (st_atime), which Bacula does not use, it will cause st_ctime to change and hence Bacula will backup the file during an Incremental or Differential backup. In the case of Sophos virus scanning, you can prevent it from resetting the access time (st_atime) and hence changing st_ctime by using the
--no-reset-atime option. For other software, please see their manual.When Bacula does an Incremental backup, all modified files that are still on the system are backed up. However, any file that has been deleted since the last Full backup remains in the Bacula catalog, which means that if between a Full save and the time you do a restore, some files are deleted, those deleted files will also be restored. The deleted files will no longer appear in the catalog after doing another Full save.
In addition, if you move a directory rather than copy it, the files in it do not have their modification time (st_mtime) or their attribute change time (st_ctime) changed. As a consequence, those files will probably not be backed up by an Incremental or Differential backup which depend solely on these time stamps. If you move a directory, and wish it to be properly backed up, it is generally preferable to copy it, then delete the original.
However, to manage deleted files or directories changes in the catalog during an Incremental backup you can use accurate mode. This is quite memory consuming process. See Accurate mode for more details.
- Differential
- When the Level is set to Differential all files specified in the FileSet that have changed since the last successful Full backup of the same Job will be backed up. If the Director cannot find a valid previous Full backup for the same Job, FileSet, and Client, backup, then the Differential job will be upgraded into a Full backup. When the Director looks for a valid Full backup record in the catalog database, it looks for a previous Job with:
- The same Job name.
- The same Client name.
- The same FileSet (any change to the definition of the FileSet such as adding or deleting a file in the Include or Exclude sections constitutes a different FileSet.
- The Job was a FULL backup.
- The Job terminated normally (i.e. did not fail or was not canceled).
- The Job started no longer ago than Max Full Interval.
If all the above conditions do not hold, the Director will upgrade the Differential to a Full save. Otherwise, the Differential backup will be performed as requested.
The File daemon (Client) decides which files to backup for a differential backup by comparing the start time of the prior Full backup Job against the time each file was last “modified” (st_mtime) and the time its attributes were last “changed” (st_ctime). If the file was modified or its attributes were changed on or after this start time, it will then be backed up. The start time used is displayed after the Since on the Job report. In rare cases, using the start time of the prior backup may cause some files to be backed up twice, but it ensures that no change is missed. As with the Incremental option, you should ensure that the clocks on your server and client are synchronized or as close as possible to avoid the possibility of a file being skipped. Note, on versions 1.33 or greater Bacula automatically makes the necessary adjustments to the time between the server and the client so that the times Bacula uses are synchronized.
When Bacula does a Differential backup, all modified files that are still on the system are backed up. However, any file that has been deleted since the last Full backup remains in the Bacula catalog, which means that if between a Full save and the time you do a restore, some files are deleted, those deleted files will also be restored. The deleted files will no longer appear in the catalog after doing another Full save. However, to remove deleted files from the catalog during a Differential backup is quite a time consuming process and not currently implemented in Bacula. It is, however, a planned future feature.
As noted above, if you move a directory rather than copy it, the files in it do not have their modification time (st_mtime) or their attribute change time (st_ctime) changed. As a consequence, those files will probably not be backed up by an Incremental or Differential backup which depend solely on these time stamps. If you move a directory, and wish it to be properly backed up, it is generally preferable to copy it, then delete the original. Alternatively, you can move the directory, then use the touch program to update the timestamps.
However, to manage deleted files or directories changes in the catalog during an Differential backup you can use accurate mode. This is quite memory consuming process. See Accurate mode for more details.
Every once and a while, someone asks why we need Differential backups as long as Incremental backups pickup all changed files. There are possibly many answers to this question, but the one that is the most important for me is that a Differential backup effectively merges all the Incremental and Differential backups since the last Full backup into a single Differential backup. This has two effects:
- It gives some redundancy since the old backups could be used if the merged backup cannot be read.
- More importantly, it reduces the number of Volumes that are needed to do a restore effectively eliminating the need to read all the volumes on which the preceding Incremental and Differential backups since the last Full are done.
- VirtualFull
- When the backup Level is set to VirtualFull, Bacula will consolidate the previous Full backup plus the most recent Differential backup and any subsequent Incremental backups into a new Full backup. This new Full backup will then be considered as the most recent Full for any future Incremental or Differential backups. The VirtualFull backup is accomplished without contacting the client by reading the previous backup data and writing it to a volume in a different pool.
Bacula's virtual backup feature is often called Synthetic Backup or Consolidation in other backup products.
For a Restore Job, no level needs to be specified.
For a Verify Job, the Level may be one of the following:
- InitCatalog
- does a scan of the specified FileSet and stores the file attributes in the Catalog database. Since no file data is saved, you might ask why you would want to do this. It turns out to be a very simple and easy way to have a Tripwire like feature using Bacula. In other words, it allows you to save the state of a set of files defined by the FileSet and later check to see if those files have been modified or deleted and if any new files have been added. This can be used to detect system intrusion. Typically you would specify a FileSet that contains the set of system files that should not change (e.g. /sbin, /boot, /lib, /bin, ...). Normally, you run the InitCatalog level verify one time when your system is first setup, and then once again after each modification (upgrade) to your system. Thereafter, when your want to check the state of your system files, you use a Verify level = Catalog. This compares the results of your InitCatalog with the current state of the files.
- Catalog
- Compares the current state of the files against the state previously saved during an InitCatalog. Any discrepancies are reported. The items reported are determined by the Verify options specified on the Include directive in the specified FileSet (see the FileSet resource below for more details). Typically this command will be run once a day (or night) to check for any changes to your system files.
Please note! If you run two Verify Catalog jobs on the same client at the same time, the results will certainly be incorrect. This is because Verify Catalog modifies the Catalog database while running in order to track new files.
- Data
Read back the data stored on volumes and check data attributes such as size and the checksum of all the files.
To run the Verify job, it is possible to use the “jobid” parameter of the “run” command.
Please note, the current Verify Data implementation requires specifying the correct Storage resource in the Verify job. The Storage resource can be changed with the bconsole command line and with the menu.
It is also possible to use the accurate option to check catalog records at the same time. When using a Verify job with level=Data and accurate=yes can replace the level=VolumeToCatalog option.
To run a Verify Job with the accurate option, it is possible to set the option in the Job definition or set use the accurate=yes on the command line.
* run job=VerifyData level=Data jobid=10 accurate=yes
- VolumeToCatalog
- This level causes Bacula to read the file attribute data written to the Volume from the last backup Job for the job specified on the VerifyJob directive. The file attribute data are compared to the values saved in the Catalogind database and any differences are reported. This is similar to the DiskToCatalog level except that instead of comparing the disk file attributes to the catalog database, the attribute data written to the Volume is read and compared to the catalog database. Although the attribute data including the signatures (MD5 or SHA1) are compared, the actual file data is not compared (it is not in the catalog).
Please note! If you run two Verify VolumeToCatalog jobs on the same client at the same time, the results will certainly be incorrect. This is because the Verify VolumeToCatalog modifies the Catalog database while running.
- DiskToCatalog
- This level causes Bacula to read the files as they currently are on disk, and to compare the current file attributes with the attributes saved in the catalog from the last backup for the job specified on the VerifyJob directive. This level differs from the VolumeToCatalog level described above by the fact that it doesn't compare against a previous Verify job but against a previous backup. When you run this level, you must supply the verify options on your Include statements. Those options determine what attribute fields are compared.
This command can be very useful if you have disk problems because it will compare the current state of your disk against the last successful backup, which may be several jobs.
Note, the current implementation (1.32c) does not identify files that have been deleted.
- Accurate = <yes|no>
- In accurate mode, the File daemon knowns exactly which files were present after the last backup. So it is able to handle deleted or renamed files.
When restoring a FileSet for a specified date (including “most recent”), Bacula is able to restore exactly the files and directories that existed at the time of the last backup prior to that date including ensuring that deleted files are actually deleted, and renamed directories are restored properly.
In this mode, the File daemon must keep data concerning all files in memory. So If you do not have sufficient memory, the backup may either be terribly slow or fail.
For 500.000 files (a typical desktop linux system), it will require approximately 64 Megabytes of RAM on your File daemon to hold the required information.
- Verify Job = <Job-Resource-Name>
- If you run a verify job without this directive, the last job run will be compared with the catalog, which means that you must immediately follow a backup by a verify command. If you specify a Verify Job Bacula will find the last job with that name that ran. This permits you to run all your backups, then run Verify jobs on those that you wish to be verified (most often a VolumeToCatalog) so that the tape just written is re-read.
- JobDefs = <JobDefs-Resource-Name>
- If a <JobDefs-Resource-Name> is specified, all the values contained in the named JobDefs resource will be used as the defaults for the current Job. Any value that you explicitly define in the current Job resource, will override any defaults specified in the JobDefs resource. The use of this directive permits writing much more compact Job resources where the bulk of the directives are defined in one or more JobDefs. This is particularly useful if you have many similar Jobs but with minor variations such as different Clients. A simple example of the use of JobDefs is provided in the default bacula-dir.conf file.
- Bootstrap = <bootstrap-file>
- The Bootstrap directive specifies a bootstrap file that, if provided, will be used during Restore Jobs and is ignored in other Job types. The <bootstrap-file> contains the list of tapes to be used in a Restore Job as well as which files are to be restored. Specification of this directive is optional, and if specified, it is used only for a restore job. In addition, when running a Restore job from the console, this value can be changed.
If you use the restore command in the bconsole program, to start a Restore job, the <bootstrap-file> will be created automatically from the files you select to be restored.
For additional details of the bootstrap directive, please see Restoring Files with the Bootstrap File chapter of this manual.
- Write Bootstrap = <bootstrap-file-specification>
- The writebootstrap directive specifies a file name where Bacula will write a bootstrap file for each Backup job run. This directive applies only to Backup Jobs. If the Backup job is a Full save, Bacula will erase any current contents of the specified file before writing the bootstrap records. If the Job is an Incremental or Differential save, Bacula will append the current bootstrap record to the end of the file.
Using this feature, permits you to constantly have a bootstrap file that can recover the current state of your system. Normally, the file specified should be a mounted drive on another machine, so that if your hard disk is lost, you will immediately have a bootstrap record available. Alternatively, you should copy the bootstrap file to another machine after it is updated. Note, it is a good idea to write a separate bootstrap file for each Job backed up including the job that backs up your catalog database.
If the <bootstrap-file-specification> begins with a vertical bar (|), Bacula will use the specification as the name of a program to which it will pipe the bootstrap record. It could for example be a shell script that emails you the bootstrap record.
On versions 1.39.22 or greater, before opening the file or executing the specified command, Bacula performs character substitution like in RunScript directive. To automatically manage your bootstrap files, you can use this in your JobDefs resources:
JobDefs { Write Bootstrap = "%c_%n.bsr" ... }For more details on using this file, please see the chapter entitled The Bootstrap File of this manual.
- Client = <client-resource-name>
- The Client directive specifies the Client (File daemon) that will be used in the current Job. Only a single Client may be specified in any one Job. The Client runs on the machine to be backed up, and sends the requested files to the Storage daemon for backup, or receives them when restoring. For additional details, see the Client Resource section of this chapter. This directive is required.
- FileSet = <FileSet-resource-name>
- The FileSet directive specifies the FileSet that will be used in the current Job. The FileSet specifies which directories (or files) are to be backed up, and what options to use (e.g. compression, ...). Only a single FileSet resource may be specified in any one Job. For additional details, see the FileSet Resource section of this chapter. This directive is required.
- Base = <job-resource-name, ...>
- The Base directive permits to specify the list of jobs that will be used during Full backup as base. This directive is optional. See the Base Job chapter for more information.
- Messages = <messages-resource-name>
- The Messages directive defines what Messages resource should be used for this job, and thus how and where the various messages are to be delivered. For example, you can direct some messages to a log file, and others can be sent by email. For additional details, see the Messages Resource Chapter of this manual. This directive is required.
- Snapshot Retention = <time-period-specification>
-
The Snapshot Retention directive defines the length of time that Bacula will keep Snapshots in the Catalog database and on the Client after the Snapshot creation. When this time period expires, and if using the snapshot prune command, Bacula will prune (remove) Snapshot records that are older than the specified Snapshot Retention period and will contact the FileDaemon to delete Snapshots from the system.
The Snapshot retention period is specified as seconds, minutes, hours, days, weeks, months, quarters, or years. See the Configuration chapter of this manual for additional details of time specification.
The default is 0 seconds, Snapshots are deleted at the end of the backup. The Job SnapshotRetention directive overwrites the Client SnapshotRetention directive.
- Pool = <pool-resource-name>
- The Pool directive defines the pool of Volumes where your data can be backed up. Many Bacula installations will use only the Default pool. However, if you want to specify a different set of Volumes for different Clients or different Jobs, you will probably want to use Pools. For additional details, see the Pool Resource section of this chapter. This directive is required.
- Full Backup Pool = <pool-resource-name>
- The Full Backup Pool specifies a Pool to be used for Full backups. It will override any Pool specification during a Full backup. This directive is optional.
- Differential Backup Pool = <pool-resource-name>
- The Differential Backup Pool specifies a Pool to be used for Differential backups. It will override any Pool specification during a Differential backup. This directive is optional.
- Incremental Backup Pool = <pool-resource-name>
- The Incremental Backup Pool specifies a Pool to be used for Incremental backups. It will override any Pool specification during an Incremental backup. This directive is optional.
- VirtualFull Backup Pool = <pool-resource-name>
- The VirtualFull Backup Pool specifies a Pool to be used for VirtualFull backups. It will override any Pool specification during an VirtualFull backup. This directive is optional.
- BackupsToKeep = <number>
-
When this directive is present during a Virtual Full (it is ignored for other Job types), it will look for a Full backup that has more subsequent backups than the value specified. In the example below, the Job will simply terminate unless there is a Full back followed by at least 31 backups of either level Differential or Incremental.
Job { Name = "VFull" Type = Backup Level = VirtualFull Client = "my-fd" File Set = "FullSet" Accurate = Yes Backups To Keep = 30 }Assuming that the last Full backup is followed by 32 Incremental backups, a Virtual Full will be run that consolidates the Full with the first two Incrementals that were run after the Full. The result is that you will end up with a Full followed by 30 Incremental backups.
- DeleteConsolidatedJobs = <yes/no>
-
If set to yes, it will cause any old Job that is consolidated during a Virtual Full to be deleted. In the example above we saw that a Full plus one other job (either an Incremental or Differential) were consolidated into a new Full backup. The original Full plus the other Job consolidated will be deleted. The default value is no.
- Schedule = <schedule-name>
- The Schedule directive defines what schedule is to be used for the Job. The schedule in turn determines when the Job will be automatically started and what Job level (i.e. Full, Incremental, ...) is to be run. This directive is optional, and if left out, the Job can only be started manually using the Console program. Although you may specify only a single Schedule resource for any one job, the Schedule resource may contain multiple Run directives, which allow you to run the Job at many different times, and each Run directive permits overriding the default Job Level Pool, Storage, and Messages resources. This gives considerable flexibility in what can be done with a single Job. For additional details, see the Schedule Resource chapter of this manual.
- Storage = <storage-resource-name>
- The Storage directive defines the name of the storage services where you want to backup the FileSet data. For additional details, see the Storage Resource Chapter of this manual. The Storage resource may also be specified in the Job's Pool resource, in which case the value in the Pool resource overrides any value in the Job. This Storage resource definition is not required by either the Job resource or in the Pool, but it must be specified in one or the other, if not an error will result. Storage can be either specified by an single item or it can be specified as a comma separated list of storages to use according to StorageGroupPolicy. If some number of first storage daemons on the list are unavailable due to network problems, broken or unreachable for some other reason, Bacula will take first available one from the list (which is sorted according to the policy used) which is network reachable and healthy.
- StorageGroupPolicy = <Storage Group Policy Name>
- Storage Group Policy determines how Storage resources (from the 'Storage' directive) are being choosen from the Storage list. If no StoragePolicy is specified Bacula always tries to use first available Storage from the provided list. Currently supported policies are:
- ListedOrder
- - This is the default policy, which uses first available storage from the list provided
- LeastUsed
- - This policy scans all storage daemons from the list and chooses the one with the least number of jobs being currently run
- FreeSpace
- - This policy queries each Storage Daemon in the list for its FreeSpace (as a sum of devices specified in the SD config) and sorts the list according to the FreeSpace returned, so that first item in the list is the SD with the biggest amount of FreeSpace while the last one in the list is the one with the least amount of FreeSpace available.
- LastBackedUpTo
- - This policy ensures that job is backed up to the storage where the same job (of the same level, i.e. Full or Incremental) has been backed up the longest time ago. The goal is to split the jobs to improve redundancy.
- LastBackupedToStore
- - This policy ensures that job is backed up on the storage where the same job (with same level i.e. Full or Incremental) has been backed up to the longest time ago. The goal is to spread the jobs to improve redundancy.
- FreeSpaceLeastUsed
- - This policy ensures that a job is backed up to the storage with the most free space and least running jobs. Within the candidates storages, the least used one will be selected. Candidate storages are determined by the StorageGroupPolicyThreshold Job directive. If MaxFreeSpace is the largest amount of free space for all storages in the group, a storage will be a candidate if its free space is above
 .
.
- StorageGroupPolicyThreshold = <Threshold size>
- Used in conjunction with the FreeSpaceLeastUsed StorageGroupePolicy to specify the range of free space Candidate storages.
- Max Start Delay = <time>
- The time specifies the maximum delay between the scheduled time and the actual start time for the Job. For example, a job can be scheduled to run at 1:00am, but because other jobs are running, it may wait to run. If the delay is set to 3600 (one hour) and the job has not begun to run by 2:00am, the job will be canceled. This can be useful, for example, to prevent jobs from running during day time hours. The default is 0 which indicates no limit.
- Max Run Time = <time>
- The time specifies the maximum allowed time that a job may run, counted from when the job starts, (not necessarily the same as when the job was scheduled).
By default, the the watchdog thread will kill any Job that has run more than 200 days. The maximum watchdog timeout is independent of MaxRunTime and cannot be changed.
- Incremental|Differential Max Wait Time = <time>
- Theses directives have been deprecated in favor of Incremental|Differential Max Run Time since bacula 2.3.18.
- Incremental Max Run Time = <time>
- The time specifies the maximum allowed time that an Incremental backup job may run, counted from when the job starts, (not necessarily the same as when the job was scheduled).
- Differential Max Run Time = <time>
- The time specifies the maximum allowed time that a Differential backup job may run, counted from when the job starts, (not necessarily the same as when the job was scheduled).
- Max Run Sched Time = <time>
-
The time specifies the maximum allowed time that a job may run, counted from when the job was scheduled. This can be useful to prevent jobs from running during working hours. We can see it like Max Start Delay + Max Run Time.
- Max Wait Time = <time>
- The time specifies the maximum allowed time that a job may block waiting for a resource (such as waiting for a tape to be mounted, or waiting for the storage or file daemons to perform their duties), counted from the when the job starts, (not necessarily the same as when the job was scheduled). This directive works as expected since bacula 2.3.18.
- Maximum Spawned Jobs = <nb>
-
The Job resource now permits specifying a number of Maximum Spawn Jobs. The default is 600. This directive can be useful if you have big hardware and you do a lot of Migration/Copy jobs which start at the same time.
- Maximum Bandwidth = <speed>
-
The speed parameter specifies the maximum allowed bandwidth in bytes that a job may use. You may specify the following speed parameter modifiers: kb/s (1,000 bytes per second), k/s (1,024 bytes per second), mb/s (1,000,000 bytes per second), or m/s (1,048,576 bytes per second).
The use of TLS, TLS PSK, CommLine compression and Deduplication can interfer with the value set with the Directive.
- Max Full Interval = <time>
- The time specifies the maximum allowed age (counting from start time) of the most recent successful Full backup that is required in order to run Incremental or Differential backup jobs. If the most recent Full backup is older than this interval, Incremental and Differential backups will be upgraded to Full backups automatically. If this directive is not present, or specified as 0, then the age of the previous Full backup is not considered.
- Max VirtualFull Interval = <time>
-
The time specifies the maximum allowed age (counting from start time) of the most recent successful Full backup that is required in order to run Incremental, Differential or Full backup jobs. If the most recent Full backup is older than this interval, Incremental, Differential and Full backups will be converted to a VirtualFull backup automatically. If this directive is not present, or specified as 0, then the age of the previous Full backup is not considered.
Please note that a VirtualFull job is not a real backup job. A VirtualFull will merge exiting jobs to create a new virtual Full job in the catalog and will copy the exiting data to new volumes.
The Client is not used in a VirtualFull job, so when using this directive, the Job that was supposed to run and save recently modified data on the Client will not run. Only the next regular Job defined in the Schedule will backup the data. It will not be possible to restore the data that was modified on the Client between the last Incremental/Differential and the VirtualFull.
- Prefer Mounted Volumes = <yes|no>
- If the Prefer Mounted Volumes directive is set to yes (default yes), the Storage daemon is requested to select either an Autochanger or a drive with a valid Volume already mounted in preference to a drive that is not ready. This means that all jobs will attempt to append to the same Volume (providing the Volume is appropriate - right Pool, ... for that job), unless you are using multiple pools. If no drive with a suitable Volume is available, it will select the first available drive. Note, any Volume that has been requested to be mounted, will be considered valid as a mounted volume by another job. This if multiple jobs start at the same time and they all prefer mounted volumes, the first job will request the mount, and the other jobs will use the same volume.
If the directive is set to no, the Storage daemon will prefer finding an unused drive, otherwise, each job started will append to the same Volume (assuming the Pool is the same for all jobs). Setting Prefer Mounted Volumes to no can be useful for those sites with multiple drive autochangers that prefer to maximize backup throughput at the expense of using additional drives and Volumes. This means that the job will prefer to use an unused drive rather than use a drive that is already in use.
Despite the above, we recommend against setting this directive to no since it tends to add a lot of swapping of Volumes between the different drives and can easily lead to deadlock situations in the Storage daemon. We will accept bug reports against it, but we cannot guarantee that we will be able to fix the problem in a reasonable time.
A better alternative for using multiple drives is to use multiple pools so that Bacula will be forced to mount Volumes from those Pools on different drives.
- Prune Jobs = <yes|no>
- Normally, pruning of Jobs from the Catalog is specified on a Client by Client basis in the Client resource with the AutoPrune directive. If this directive is specified (not normally) and the value is yes, it will override the value specified in the Client resource. The default is no.
- Prune Files = <yes|no>
- Normally, pruning of Files from the Catalog is specified on a Client by Client basis in the Client resource with the AutoPrune directive. If this directive is specified (not normally) and the value is yes, it will override the value specified in the Client resource. The default is no.
- Prune Volumes = <yes|no>
- Normally, pruning of Volumes from the Catalog is specified on a Pool by Pool basis in the Pool resource with the AutoPrune directive. Note, this is different from File and Job pruning which is done on a Client by Client basis. If this directive is specified (not normally) and the value is yes, it will override the value specified in the Pool resource. The default is no.
- RunScript {<body-of-runscript>}
-
The RunScript directive behaves like a resource in that it requires opening and closing braces around a number of directives that make up the body of the runscript.
The specified Command (see below for details) is run as an external program prior or after the current Job. This is optional. By default, the program is executed on the Client side like in ClientRunXXXJob.
Console options are special commands that are sent to the director instead of the OS. At this time, console command ouputs are redirected to log with the jobid 0.
You can use following console command : delete, disable, enable, estimate, list, llist, memory, prune, purge, reload, status, setdebug, show, time, trace, update, version, .client, .jobs, .pool, .storage. See console chapter for more information. You need to specify needed information on command line, nothing will be prompted. Example :
Console = "prune files client=%c" Console = "update stats age=3"
You can specify more than one Command/Console option per RunScript.
You can use following options may be specified in the body of the runscript:
Options for Run Script Options Value Default Information Runs On Success Yes / No Yes Run command if JobStatus is successful Runs On Failure Yes / No No Run command if JobStatus isn't successful Runs On Client Yes / No Yes Run command on clientnoteScripts will run on Client only with Jobs that use a Client. (Backup, Restore, some Verify jobs). For other Jobs (Copy, Migration, Admin, ...) RunsOnClient should be set to No. Runs When Before After Always AfterVSS AtJobCompletion Never When run commands Fail Job On Error Yes/No Yes Fail job if script returns something different from 0 Command Path to your script Console Console command Any output sent by the command to standard output will be included in the Bacula job report. The command string must be a valid program name or name of a shell script.
In addition, the command string is parsed then fed to the OS, which means that the path will be searched to execute your specified command, but there is no shell interpretation, as a consequence, if you invoke complicated commands or want any shell features such as redirection or piping, you must call a shell script and do it inside that script.
Before submitting the specified command to the operating system, Bacula performs character substitution of the following characters:
%% = % %b = Job Bytes %c = Client's name %C = If the job is a Cloned job (Only on director side) %d = Daemon's name (Such as host-dir or host-fd) %D = Director's name (Also valid on file daemon) %e = Job Exit Status %E = Non-fatal Job Errors %f = Job FileSet (Only on director side) %F = Job Files %h = Client address %i = JobId %I = Migration/Copy JobId (Only in Copy/Migrate Jobs) %j = Unique Job id %l = Job Level %n = Job name %o = Job Priority %p = Pool name (Only on director side) %P = Current PID process %R = Read Bytes %s = Since time %S = Previous Job name (Only on file daemon side) %t = Job type (Backup, ...) %v = Volume name (Only on director side) %w = Storage name (Only on director side) %x = Spooling enabled? ("yes" or "no")Some character substitutions are not available in all situations. The Job Exit Status code %e edits the following values:
- OK
- Error
- Fatal Error
- Canceled
- Differences
- Unknown term code
Thus if you edit it on a command line, you will need to enclose it within some sort of quotes.
You can use these following shortcuts:
Examples:RunScript shortcuts Runs Runs FailJob Runs Runs Keyword On On On On When Success Failure Error Client Run Before Job Yes No Before Run After Job Yes No No After Run After Failed Job No Yes No After Client Run Before Job Yes Yes Before Client Run After Job Yes No Yes After RunScript { RunsWhen = Before FailJobOnError = No Command = "/etc/init.d/apache stop" } RunScript { RunsWhen = After RunsOnFailure = yes Command = "/etc/init.d/apache start" }Notes about ClientRunBeforeJob
For compatibility reasons, with this shortcut, the command is executed directly when the client recieve it. And if the command is in error, other remote runscripts will be discarded. To be sure that all commands will be sent and executed, you have to use RunScript syntax.
Special Shell Considerations
A “Command =” can be one of:
- The full path to an executable program
- The name of an executable program that can be found in the $PATH
- A complex shell command in the form of: "sh -c \"your commands go here\""
You can run scripts just after snapshots initializations with AfterVSS keyword.
In addition, for a Windows client, please take note that you must ensure a correct path to your script. The script or program can be a .com, .exe or a .bat file. If you just put the program name in then Bacula will search using the same rules that cmd.exe uses (current directory, Bacula bin directory, and PATH). It will even try the different extensions in the same order as cmd.exe. The command can be anything that cmd.exe or command.com will recognize as an executable file.
However, if you have slashes in the program name then Bacula figures you are fully specifying the name, so you must also explicitly add the three character extension.
The command is run in a Win32 environment, so Unix like commands will not work unless you have installed and properly configured Cygwin in addition to and separately from Bacula.
The System %Path% will be searched for the command. (under the environment variable dialog you have have both System Environment and User Environment, we believe that only the System environment will be available to bacula-fd, if it is running as a service.)
System environment variables can be referenced with %var% and used as either part of the command name or arguments.
So if you have a script in the Bacula \bin directory then the following lines should work fine:
Client Run Before Job = systemstate or Client Run Before Job = systemstate.bat or Client Run Before Job = "systemstate" or Client Run Before Job = "systemstate.bat" or ClientRunBeforeJob = "\"C:/Program Files/Bacula/systemstate.bat\""The outer set of quotes is removed when the configuration file is parsed. You need to escape the inner quotes so that they are there when the code that parses the command line for execution runs so it can tell what the program name is.
ClientRunBeforeJob = "\"C:/Program Files/Software Vendor/Executable\" /arg1 /arg2 \"foo bar\""The special characters
&<>()@^|
will need to be quoted, if they are part of a filename or argument.If someone is logged in, a blank “command” window running the commands will be present during the execution of the command.
Some Suggestions from Phil Stracchino for running on Win32 machines with the native Win32 File daemon:
- You might want the ClientRunBeforeJob directive to specify a .bat file which runs the actual client-side commands, rather than trying to run (for example) regedit /e directly.
- The batch file should explicitly “exit 0” on successful completion.
- The path to the batch file should be specified in Unix form:
ClientRunBeforeJob = "c:/bacula/bin/systemstate.bat"
rather than DOS/Windows form:ClientRunBeforeJob = "c:\bacula\bin\systemstate.bat" # INCORRECT
For Win32, please note that there are certain limitations:
ClientRunBeforeJob = "C:/Program Files/Bacula/bin/pre-exec.bat"
Lines like the above do not work because there are limitations of cmd.exe that is used to execute the command. Bacula prefixes the string you supply with cmd.exe /c . To test that your command works you should type cmd /c "C:/Program Files/test.exe" at a cmd prompt and see what happens. Once the command is correct insert a backslash (\) before each double quote ("), and then put quotes around the whole thing when putting it in the director's configuration file. You either need to have only one set of quotes or else use the short name and don't put quotes around the command path.
Below is the output from cmd's help as it relates to the command line passed to the /c option.
If /C or /K is specified, then the remainder of the command line after the switch is processed as a command line, where the following logic is used to process quote (") characters:
- If all of the following conditions are met, then quote characters on the command line are preserved:
- no /S switch.
- exactly two quote characters.
- no special characters between the two quote characters, where special is one of:
&<>()@^|
- there are one or more whitespace characters between the the two quote characters.
- the string between the two quote characters is the name of an executable file.
- Otherwise, old behavior is to see if the first character is a quote character and if so, strip the leading character and remove the last quote character on the command line, preserving any text after the last quote character.
The following example of the use of the Client Run Before Job directive was submitted by a user:
You could write a shell script to back up a DB2 database to a FIFO. The shell script is:
#!/bin/sh # ===== backupdb.sh DIR=/u01/mercuryd mkfifo $DIR/dbpipe db2 BACKUP DATABASE mercuryd TO $DIR/dbpipe WITHOUT PROMPTING & sleep 1
The following line in the Job resource in the bacula-dir.conf file:
Client Run Before Job = "su - mercuryd -c \"/u01/mercuryd/backupdb.sh '%t' '%l'\""
When the job is run, you will get messages from the output of the script stating that the backup has started. Even though the command being run is backgrounded with &, the job will block until the db2 BACKUP DATABASE command, thus the backup stalls.
To remedy this situation, the “db2 BACKUP DATABASE” line should be changed to the following:
db2 BACKUP DATABASE mercuryd TO $DIR/dbpipe WITHOUT PROMPTING > $DIR/backup.log 2>&1 < /dev/null &
It is important to redirect the input and outputs of a backgrounded command to /dev/null to prevent the script from blocking.
- Run Before Job = <command>
- The specified <command> is run as an external program prior to running the current Job. This directive is not required, but if it is defined, and if the exit code of the program run is non-zero, the current Bacula job will be canceled.
Run Before Job = "echo test"
it's equivalent to :RunScript { Command = "echo test" RunsOnClient = No RunsWhen = Before }Lutz Kittler has pointed out that using the RunBeforeJob directive can be a simple way to modify your schedules during a holiday. For example, suppose that you normally do Full backups on Fridays, but Thursday and Friday are holidays. To avoid having to change tapes between Thursday and Friday when no one is in the office, you can create a RunBeforeJob that returns a non-zero status on Thursday and zero on all other days. That way, the Thursday job will not run, and on Friday the tape you inserted on Wednesday before leaving will be used.
- Run After Job = <Command>
- The specified <Command> is run as an external program if the current job terminates normally (without error or without being canceled). This directive is not required. If the exit code of the program run is non-zero, Bacula will print a warning message. Before submitting the specified command to the operating system, Bacula performs character substitution as described above for the RunScript directive.
An example of the use of this directive is given in the Tips chapter of the Bacula Enterprise Problems Resolution guide.
See the Run After Failed Job if you want to run a script after the job has terminated with any non-normal status.
- Run After Failed Job = <Command>
- The specified <Command> is run as an external program after the current job terminates with any error status. This directive is not required. The command string must be a valid program name or name of a shell script. If the exit code of the program run is non-zero, Bacula will print a warning message. Before submitting the specified command to the operating system, Bacula performs character substitution as described above for the RunScript directive. Note, if you wish that your script will run regardless of the exit status of the Job, you can use this :
RunScript { Command = "echo test" RunsWhen = After RunsOnFailure = yes RunsOnClient = no RunsOnSuccess = yes # default, you can drop this line }An example of the use of this directive is given in the Tips chapter of the Bacula Enterprise Problems Resolution guide.
- Client Run Before Job = <Command>
-
This directive is the same as Run Before Job except that the program is run on the client machine. The same restrictions apply to Unix systems as noted above for the RunScript. ClientRunBeforeJob can be used with Backup and Restore jobs.
- Client Run After Job = <Command>
- The specified <Command> is run on the client machine as soon as data spooling is complete in order to allow restarting applications on the client as soon as possible. ClientRunBeforeJob can be used with Backup and Restore jobs.
Note, please see the notes above in RunScript concerning Windows clients.
- Rerun Failed Levels = <yes|no>
- If this directive is set to yes (default no), and Bacula detects that a previous job at a higher level (i.e. Full or Differential) has failed, the current job level will be upgraded to the higher level. This is particularly useful for Laptops where they may often be unreachable, and if a prior Full save has failed, you wish the very next backup to be a Full save rather than whatever level it is started as.
There are several points that must be taken into account when using this directive: first, a failed job is defined as one that has not terminated normally, which includes any running job of the same name (you need to ensure that two jobs of the same name do not run simultaneously); secondly, the Ignore FileSet Changes directive is not considered when checking for failed levels, which means that any FileSet change will trigger a rerun.
- Spool Data = <yes|no>
-
If this directive is set to yes (default no), the Storage daemon will be requested to spool the data for this Job to disk rather than write it directly to the Volume (normally a tape).
Thus the data is written in large blocks to the Volume rather than small blocks. This directive is particularly useful when running multiple simultaneous backups to tape. Once all the data arrives or the spool files' maximum sizes are reached, the data will be despooled and written to tape.
Spooling data prevents interleaving date from several job and reduces or eliminates tape drive stop and start commonly known as “shoe-shine”.
We don't recommend using this option if you are writing to a disk file using this option will probably just slow down the backup jobs.
NOTE: When this directive is set to yes, Spool Attributes is also automatically set to yes.
- Spool Attributes = <yes|no>
-
The default is set to yes, the Storage daemon will buffer the File attributes and Storage coordinates to a temporary file in the Working Directory, then when writing the Job data to the tape is completed, the attributes and storage coordinates will be sent to the Director. If set to no the File attributes are sent by the Storage daemon to the Director as they are stored on tape.
NOTE: When Spool Data is set to yes, Spool Attributes is also automatically set to yes.
- SpoolSize=bytes
- where the bytes specify the maximum spool size for this job. The default is take from Device Maximum Spool Size limit. This directive is available only in Bacula version 2.3.5 or later.
- Where = <directory>
- This directive applies only to a Restore job and specifies a prefix to the directory name of all files being restored. This permits files to be restored in a different location from which they were saved. If Where is not specified or is set to slash (/), the files will be restored to their original location. By default, we have set Where in the example configuration files to be /tmp/bacula-restores. This is to prevent accidental overwriting of your files.
- Add Prefix = <directory>
- This directive applies only to a Restore job and specifies a prefix to the directory name of all files being restored. This will use File Relocation feature implemented in Bacula 2.1.8 or later.
- Add Suffix = <extention>
- This directive applies only to a Restore job and specifies a suffix to all files being restored. This will use File Relocation feature implemented in Bacula 2.1.8 or later.
Using Add Suffix=.old, /etc/passwd will be restored to /etc/passwsd.old
- Strip Prefix = <directory>
- This directive applies only to a Restore job and specifies a prefix to remove from the directory name of all files being restored. This will use the File Relocation feature implemented in Bacula 2.1.8 or later.
Using Strip Prefix=/etc, /etc/passwd will be restored to /passwd
Under Windows, if you want to restore c:/files to d:/files, you can use :
Strip Prefix = c: Add Prefix = d:
- RegexWhere = <expressions>
- This directive applies only to a Restore job and specifies a regex filename manipulation of all files being restored. This will use File Relocation feature implemented in Bacula 2.1.8 or later.
For more informations about how use this option, see this.
- Replace = <replace-option>
- This directive applies only to a Restore job and specifies what happens when Bacula wants to restore a file or directory that already exists. You have the following options for <replace-option>:
- RestoreClient = <client-resource-name>
-
The RestoreClient directive specifies the default Client (File Daemon) that will be used with the restore job. If this directive is not set then a default restore client will be set to a backup client as usual. It is possible to define a dedicated restore job and run an automatic (scheduled) restore tests of your backups which will be redirected to the restore test Client.
- always
- when the file to be restored already exists, it is deleted and then replaced by the copy that was backed up. This is the default value.
- ifnewer
- if the backed up file (on tape) is newer than the existing file, the existing file is deleted and replaced by the back up.
- ifolder
- if the backed up file (on tape) is older than the existing file, the existing file is deleted and replaced by the back up.
- never
- if the backed up file already exists, Bacula skips restoring this file.
- Prefix Links=<yes|no>
- If a Where path prefix is specified for a recovery job, apply it to absolute links as well. The default is no. When set to yes then while restoring files to an alternate directory, any absolute soft links will also be modified to point to the new alternate directory. Normally this is what is desired - i.e. everything is self consistent. However, if you wish to later move the files to their original locations, all files linked with absolute names will be broken.
- Maximum Concurrent Jobs = <number>
- where <number> is the maximum number of Jobs from the current Job resource that can run concurrently. Note, this directive limits only Jobs with the same name as the resource in which it appears. Any other restrictions on the maximum concurrent jobs such as in the Director, Client, or Storage resources will also apply in addition to the limit specified here. The default is set to 1, but you may set it to a larger number. We strongly recommend that you read the WARNING documented under Maximum Concurrent Jobs in the Director's resource.
- Reschedule On Error = <yes|no>
- If this directive is enabled, and the job terminates in error, the job will be rescheduled as determined by the Reschedule Interval and Reschedule Times directives. If you cancel the job, it will not be rescheduled. The default is no (i.e. the job will not be rescheduled).
This specification can be useful for portables, laptops, or other machines that are not always connected to the network or switched on.
- Reschedule Incomplete Jobs = <yes|no>
-
If this directive is enabled, and the job terminates in incomplete status, the job will be rescheduled as determined by the Reschedule Interval and Reschedule Times directives. If you cancel the job, it will not be rescheduled. The default is yes (i.e. Incomplete jobs will be rescheduled).
- Reschedule Interval = <time-specification>
- If you have specified Reschedule On Error = yes and the job terminates in error, it will be rescheduled after the interval of time specified by <time-specification>. See the time specification formats in the Configure chapter for details of time specifications. If no interval is specified, the job will not be rescheduled on error. The default Reschedule Interval is 30 minutes (1800 seconds).
- Reschedule Times = <count>
- This directive specifies the maximum number of times to reschedule the job. If it is set to zero (0, the default) the job will be rescheduled an indefinite number of times.
- Allow Incomplete Jobs = <yes|no>
-
If this directive is disabled, and the job terminates in incomplete status, the data of the job will be discarded and the job will be marked in error. Bacula will treat this job like a regular job in error. The default is yes.
- Allow Duplicate Jobs = <yes|no>
- A duplicate job in the sense we use it here means a second or subsequent job with the same name starts. This happens most frequently when the first job runs longer than expected because no tapes are available. The default is yes.
If this directive is enabled duplicate jobs will be run. If the directive is set to no then only one job of a given name may run at one time, and the action that Bacula takes to ensure only one job runs is determined by the other directives (see below).
If Allow Duplicate Jobs is set to no and two jobs are present and none of the three directives given below permit cancelling a job, then the current job (the second one started) will be cancelled.
- Allow Higher Duplicates = <yes|no>
- This directive was implemented in version 5.0.0, but does not work as expected. If used, it should always be set to no. In later versions of Bacula the directive is disabled (disregarded).
- Cancel Lower Level Duplicates = <yes|no>
- If Allow Duplicate Jobs is set to no and this directive is set to yes, Bacula will choose between duplicated jobs the one with the highest level. For example, it will cancel a previous Incremental to run a Full backup. It works only for Backup jobs. The default is no. If the levels of the duplicated jobs are the same, nothing is done and the other Cancel XXX Duplicate directives will be examined.
- Cancel Queued Duplicates = <yes|no>
- If Allow Duplicate Jobs is set to no and if this directive is set to yes any job that is already queued to run but not yet running will be canceled. The default is no.
- Cancel Running Duplicates = <yes|no>
- If Allow Duplicate Jobs is set to no and if this directive is set to yes any job that is already running will be canceled. The default is no.
- Run = <job-name>
- The Run directive (not to be confused with the Run option in a Schedule) allows you to start other jobs or to clone jobs. By using the cloning keywords (see below), you can backup the same data (or almost the same data) to two or more drives at the same time. The <job-name> is normally the same name as the current Job resource (thus creating a clone). However, it may be any Job name, so one job may start other related jobs.
The part after the equal sign must be enclosed in double quotes, and can contain any string or set of options (overrides) that you can specify when entering the run command from the console. For example storage=DDS-4 .... In addition, there are two special keywords that permit you to clone the current job. They are level=%l and since=%s. The %l in the level keyword permits entering the actual level of the current job and the %s in the since keyword permits putting the same time for comparison as used on the current job. Note, in the case of the since keyword, the %s must be enclosed in double quotes, and thus they must be preceded by a backslash since they are already inside quotes. For example:
run = "Nightly-backup level=%l since=\"%s\" storage=DDS-4"
A cloned job will not start additional clones, so it is not possible to recurse.
Please note that all cloned jobs, as specified in the Run directives are submitted for running before the original job is run (while it is being initialized). This means that any clone job will actually start before the original job, and may even block the original job from starting until the original job finishes unless you allow multiple simultaneous jobs. Even if you set a lower priority on the clone job, if no other jobs are running, it will start before the original job.
If you are trying to prioritize jobs by using the clone feature (Run directive), you will find it much easier to do using a RunScript resource, or a RunBeforeJob directive.
- Priority = <number>
- This directive permits you to control the order in which your jobs will be run by specifying a positive non-zero number. The higher the number, the lower the job priority. Assuming you are not running concurrent jobs, all queued jobs of priority 1 will run before queued jobs of priority 2 and so on, regardless of the original scheduling order.
The priority only affects waiting jobs that are queued to run, not jobs that are already running. If one or more jobs of priority 2 are already running, and a new job is scheduled with priority 1, the currently running priority 2 jobs must complete before the priority 1 job is run, unless Allow Mixed Priority is set.
The default priority is 10.
If you want to run concurrent jobs you should keep these points in mind:
- See Running Concurrent Jobs section on how to setup concurrent jobs in the Bacula Enterprise Problems Resolution guide.
- Bacula concurrently runs jobs of only one priority at a time. It will not simultaneously run a priority 1 and a priority 2 job.
- If Bacula is running a priority 2 job and a new priority 1 job is scheduled, it will wait until the running priority 2 job terminates even if the Maximum Concurrent Jobs settings would otherwise allow two jobs to run simultaneously.
- Suppose that bacula is running a priority 2 job and a new priority 1 job is scheduled and queued waiting for the running priority 2 job to terminate. If you then start a second priority 2 job, the waiting priority 1 job will prevent the new priority 2 job from running concurrently with the running priority 2 job. That is: as long as there is a higher priority job waiting to run, no new lower priority jobs will start even if the Maximum Concurrent Jobs settings would normally allow them to run. This ensures that higher priority jobs will be run as soon as possible.
If you have several jobs of different priority, it may not best to start them at exactly the same time, because Bacula must examine them one at a time. If by Bacula starts a lower priority job first, then it will run before your high priority jobs. If you experience this problem, you may avoid it by starting any higher priority jobs a few seconds before lower priority ones. This insures that Bacula will examine the jobs in the correct order, and that your priority scheme will be respected.
- See Running Concurrent Jobs section on how to setup concurrent jobs in the Bacula Enterprise Problems Resolution guide.
- Allow Mixed Priority = <yes|no>
- This directive is only implemented in version 2.5 and later. When set to yes (default no), this job may run even if lower priority jobs are already running. This means a high priority job will not have to wait for other jobs to finish before starting. The scheduler will only mix priorities when all running jobs have this set to true.
Note that only higher priority jobs will start early. Suppose the director will allow two concurrent jobs, and that two jobs with priority 10 are running, with two more in the queue. If a job with priority 5 is added to the queue, it will be run as soon as one of the running jobs finishes. However, new priority 10 jobs will not be run until the priority 5 job has finished.

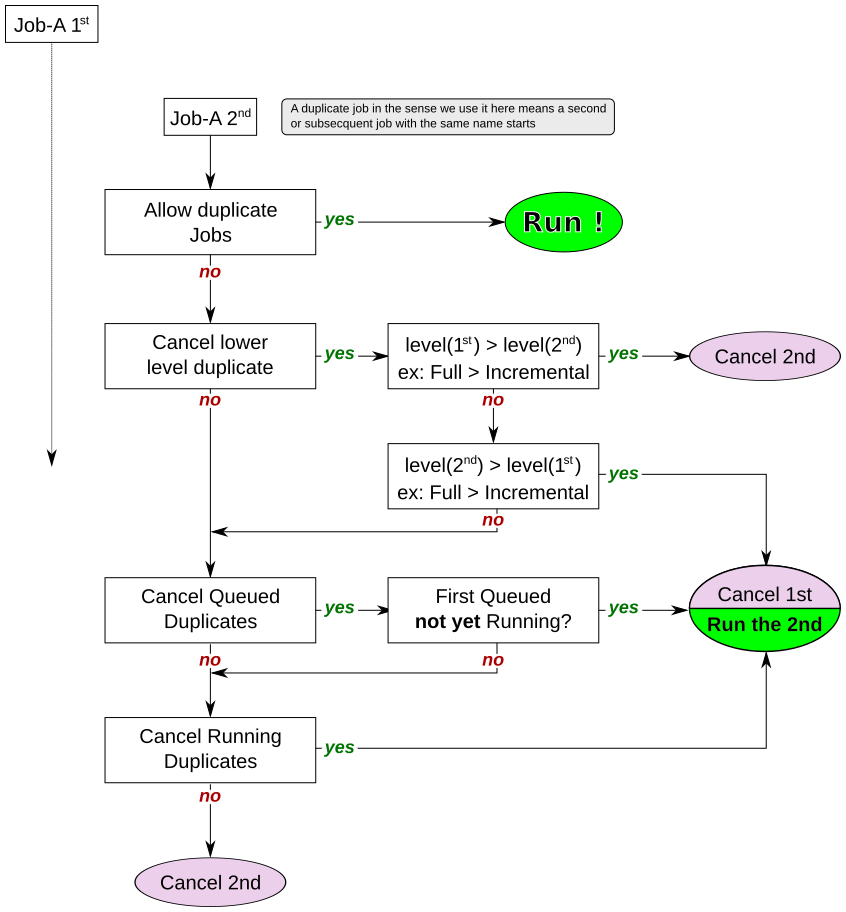
The following is an example of a valid Job resource definition:
Job {
Name = "Minou"
Type = Backup
Level = Incremental # default
Client = Minou
FileSet="Minou Full Set"
Storage = DLTDrive
Pool = Default
Schedule = "MinouWeeklyCycle"
Messages = Standard
}
The JobDefs Resource
The JobDefs resource permits all the same directives that can appear in a Job resource. However, a JobDefs resource does not create a Job, rather it can be referenced within a Job to provide defaults for that Job. This permits you to concisely define several nearly identical Jobs, each one referencing a JobDefs resource which contains the defaults. Only the changes from the defaults need to be mentioned in each Job.
The Schedule Resource
The Schedule resource provides a means of automatically scheduling a Job as well as the ability to override the default Level, Pool, Storage and Messages resources. If a Schedule resource is not referenced in a Job, the Job can only be run manually. In general, you specify an action to be taken and when.
- Schedule
- Start of the Schedule directives. No Schedule resource is required, but you will need at least one if you want Jobs to be automatically started.
- Name = <name>
- The name of the schedule being defined. The Name directive is required.
- Enabled = <yes|no>
- This directive allows you to enable or disable the Schedule resource.
- Run = <Job-overrides> <Date-time-specification>
- The Run directive defines when a Job is to be run, and what overrides if any to apply. You may specify multiple Run directives within a Schedule resource. If you do, they will all be applied (i.e. multiple schedules). If you have two Run directives that start at the same time, two Jobs will start at the same time (well, within one second of each other).
The Job-overrides permit overriding the Level, the Storage, the Messages, and the Pool specifications provided in the Job resource. In addition, the FullPool, the IncrementalPool, and the DifferentialPool specifications permit overriding the Pool specification according to what backup Job Level is in effect.
By the use of overrides, you may customize a particular Job. For example, you may specify a Messages override for your Incremental backups that outputs messages to a log file, but for your weekly or monthly Full backups, you may send the output by email by using a different Messages override.
Job-overrides are specified as: keyword=value where the keyword is Level, Storage, Messages, Pool, FullPool, DifferentialPool, or IncrementalPool, and the value is as defined on the respective directive formats for the Job resource. You may specify multiple Job-overrides on one Run directive by separating them with one or more spaces or by separating them with a trailing comma. For example:
- Level=Full
- is all files in the FileSet whether or not they have changed.
- Level=Incremental
- is all files that have changed since the last backup.
- Pool=Weekly
- specifies to use the Pool named Weekly.
- Storage=DLT_Drive
- specifies to use DLT_Drive for the storage device.
- Messages=Verbose
- specifies to use the Verbose message resource for the Job.
- FullPool=Full
- specifies to use the Pool named Full if the job is a full backup, or is upgraded from another type to a Full backup.
- DifferentialPool=Differential
- specifies to use the Pool named Differential if the job is a differential backup.
- IncrementalPool=Incremental
- specifies to use the Pool named Incremental if the job is an incremental backup.
- Next Pool = <pool-specification>
- The Next Pool directive specifies the pool to which Jobs will be migrated. This directive is used to define the Pool into which the data will be migrated.
- Priority = <number>
- This directive permits you to control the order in which your jobs will be run by specifying a positive non-zero number. The higher the number, the lower the job priority. Assuming you are not running concurrent jobs, all queued jobs of priority 1 will run before queued jobs of priority 2 and so on, regardless of the original scheduling order.
The priority only affects waiting jobs that are queued to run, not jobs that are already running. If one or more jobs of priority 2 are already running, and a new job is scheduled with priority 1, the currently running priority 2 jobs must complete before the priority 1 job is run, unless Allow Mixed Priority is set.
The default priority is 10.
See (here) for more information.
Basically, you must supply a month, day, hour, and minute the Job is to be run. Of these four items to be specified, day is special in that you may either specify a day of the month such as 1, 2, ... 31, or you may specify a day of the week such as Monday, Tuesday, ... Sunday. Finally, you may also specify a week qualifier to restrict the schedule to the first, second, third, fourth, fifth or sixth week of the month.
For example, if you specify only a day of the week, such as Tuesday the Job will be run every hour of every Tuesday of every Month. That is the month and hour remain set to the defaults of every month and all hours.
Note, by default with no other specification, your job will run at the beginning of every hour. If you wish your job to run more than once in any given hour, you will need to specify multiple Run specifications each with a different minute.
The date/time to run the Job can be specified in the following way in pseudo-BNF:
<void-keyword> = on <at-keyword> = at <week-keyword> = 1st | 2nd | 3rd | 4th | 5th | 6th | first | second | third | fourth | fifth <wday-keyword> = sun | mon | tue | wed | thu | fri | sat | sunday | monday | tuesday | wednesday | thursday | friday | saturday <week-of-year-keyword> = w00 | w01 | ... w52 | w53 <month-keyword> = jan | feb | mar | apr | may | jun | jul | aug | sep | oct | nov | dec | january | february | ... | december <daily-keyword> = daily <weekly-keyword> = weekly <monthly-keyword> = monthly <hourly-keyword> = hourly <digit> = 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 <number> = <digit> | <digit><number> <12hour> = 0 | 1 | 2 | ... 12 <hour> = 0 | 1 | 2 | ... 23 <minute> = 0 | 1 | 2 | ... 59 <day> = 1 | 2 | ... 31 | lastday <time> = <hour>:<minute> | <12hour>:<minute>am | <12hour>:<minute>pm <time-spec> = <at-keyword> <time> | <hourly-keyword> <date-keyword> = <void-keyword> <weekly-keyword> <day-range> = <day>-<day> <month-range> = <month-keyword>-<month-keyword> <wday-range> = <wday-keyword>-<wday-keyword> <range> = <day-range> | <month-range> | <wday-range> <date> = <date-keyword> | <day> | <range> <date-spec> = <date> | <date-spec> <day-spec> = <day> | <wday-keyword> | <day> | <wday-range> | <week-keyword> <wday-keyword> | <week-keyword> <wday-range> | <daily-keyword> <month-spec> = <month-keyword> | <month-range> | <monthly-keyword> <date-time-spec> = <month-spec> <day-spec> <time-spec>
Note, the Week of Year specification wnn follows the ISO standard definition of the week of the year, where Week 1 is the week in which the first Thursday of the year occurs, or alternatively, the week which contains the 4th of January. Weeks are numbered w01 to w53. w00 for Bacula is the week that precedes the first ISO week (i.e. has the first few days of the year if any occur before Thursday). w00 is not defined by the ISO specification. A week starts with Monday and ends with Sunday.
According to the US National Institute of Standards and Technology (NIST), 12am and 12pm are ambiguous and can be defined to anything. However, 12:01am is the same as 00:01 and 12:01pm is the same as 12:01, so Bacula defines 12am as 00:00 (midnight) and 12pm as 12:00 (noon). You can avoid this abiguity (confusion) by using 24 hour time specifications (i.e. no am/pm). This is the definition in Bacula version 2.0.3 and later.
An example schedule resource that is named WeeklyCycle and runs a job with level full each Sunday at 2:05am and an incremental job Monday through Saturday at 2:05am is:
Schedule {
Name = "WeeklyCycle"
Run = Level=Full sun at 2:05
Run = Level=Incremental mon-sat at 2:05
}
An example of a possible monthly cycle is as follows:
Schedule {
Name = "MonthlyCycle"
Run = Level=Full Pool=Monthly 1st sun at 2:05
Run = Level=Differential 2nd-5th sun at 2:05
Run = Level=Incremental Pool=Daily mon-sat at 2:05
}
The first of every month:
Schedule {
Name = "First"
Run = Level=Full on 1 at 2:05
Run = Level=Incremental on 2-31 at 2:05
}
The last day of February (28th or 29th), on May 31st and September 30rd at 20:00. In show schedule output, LastDay is printed as “31”
Schedule {
Name = "Last"
Run = Level=Full on lastday Feb, May, Sep at 20:00
}
Every 10 minutes:
Schedule {
Name = "TenMinutes"
Run = Level=Full hourly at 0:05
Run = Level=Full hourly at 0:15
Run = Level=Full hourly at 0:25
Run = Level=Full hourly at 0:35
Run = Level=Full hourly at 0:45
Run = Level=Full hourly at 0:55
}
Technical Notes on Schedules
Internally Bacula keeps a schedule as a bit mask. There are six masks and a minute field to each schedule. The masks are hour, day of the month (mday), month, day of the week (wday), week of the month (wom), and week of the year (woy). The schedule is initialized to have the bits of each of these masks set, which means that at the beginning of every hour, the job will run. When you specify a month for the first time, the mask will be cleared and the bit corresponding to your selected month will be selected. If you specify a second month, the bit corresponding to it will also be added to the mask. Thus when Bacula checks the masks to see if the bits are set corresponding to the current time, your job will run only in the two months you have set. Likewise, if you set a time (hour), the hour mask will be cleared, and the hour you specify will be set in the bit mask and the minutes will be stored in the minute field.
For any schedule you have defined, you can see how these bits are set by doing a show schedules command in the Console program. Please note that the bit mask is zero based, and Sunday is the first day of the week (bit zero).
The FileSet Resource
The FileSet resource defines what files are to be included or excluded in a backup job. A FileSet resource is required for each backup Job. It consists of a list of files or directories to be included, a list of files or directories to be excluded and the various backup options such as compression, encryption, and signatures that are to be applied to each file.
Any change to the list of the included files will cause Bacula to automatically create a new FileSet (defined by the name and an MD5 checksum of the Include/Exclude contents). Each time a new FileSet is created, Bacula will ensure that the next backup is always a Full save.
Bacula is designed to handle most character sets of the world, US ASCII, German, French, Chinese, ... However, it does this by encoding everything in UTF-8, and it expects all configuration files (including those read on Win32 machines) to be in UTF-8 format. UTF-8 is typically the default on Linux machines, but not on all Unix machines, nor on Windows, so you must take some care to ensure that your locale is set properly before starting Bacula. On most modern Win32 machines, you can edit the conf files with notepad and choose output encoding UTF-8.
To ensure that Bacula configuration files can be correctly read including foreign characters the LANG environment variable must end in .UTF-8. A full example is en_US.UTF-8. The exact syntax may vary a bit from OS to OS, and exactly how you define it will also vary.
Bacula assumes that all filenames are in UTF-8 format on Linux and Unix machines. On Win32 they are in Unicode (UTF-16), and will be automatically converted to UTF-8 format.
- FileSet
- Start of the FileSet resource. One FileSet resource must be defined for each Backup job.
- Name = <name>
- The name of the FileSet resource. This directive is required.
- Ignore FileSet Changes = <yes|no>
- Normally, if you modify the FileSet Include or Exclude lists, the next backup will be forced to a Full so that Bacula can guarantee that any additions or deletions are properly saved.
We strongly recommend against setting this directive to yes, since doing so may cause you to have an incomplete set of backups.
If this directive is set to yes, any changes you make to the FileSet Include or Exclude lists, will not force a Full during subsequent backups. Note that any changes to Options resources in the FileSet are not considered by this directive. You can use the Accurate mode for this to be treated correctly, or schedule a new Full backup manually.
The default is no, in which case, if you change the Include or Exclude lists, Bacula will force a Full backup to ensure that everything is properly backed up.
- Enable VSS = <yes|no>
- If this directive is set to yes the File daemon will be notified that the user wants to use a Volume Snapshot Service (VSS) backup for this job. The default is yes. This directive is effective only for VSS enabled Win32 File daemons. It permits a consistent copy of open files to be made for cooperating writer applications, and for applications that are not VSS aware, Bacula can at least copy open files. The Volume Snapshot Servicewill only be done on Windows drives where the drive (e.g. C:, D:, ...) is explicitly mentioned in a File directive. For more information, please see the Windows chapter of this manual.
- Enable Snapshot = <yes|no>
- If this directive is set to yes the File daemon will be notified that the user wants to use the Snapshot Engine for this job. The default is no. This directive is effective only for Snapshot enabled Unix File daemons. It permits a consistent copy of open files to be made for cooperating applications. The bsnapshot tool should be installed on the Client.
- Include {Options {<file-options>} ...; <file-list> }
- Exclude {<file-list> }
The Include resource must contain a list of directories and/or files to be processed in the backup job. Normally, all files found in all subdirectories of any directory in the Include File list will be backed up. Note, see below for the definition of <file-list>. The Include resource may also contain one or more Options resources that specify options such as compression to be applied to all or any subset of the files found when processing the file-list for backup. Please see below for more details concerning Options resources.
There can be any number of Include resources within the FileSet, each having its own list of directories or files to be backed up and the backup options defined by one or more Options resources. The file-list consists of one file or directory name per line. Directory names should be specified without a trailing slash with Unix path notation.
Windows users, please take note to specify directories (even c:/...) in Unix path notation. If you use Windows conventions, you will most likely not be able to restore your files due to the fact that the Windows path separator was defined as an escape character long before Windows existed, and Bacula adheres to that convention (i.e.
means the next character appears as itself).
You should always specify a full path for every directory and file that you list in the FileSet. In addition, on Windows machines, you should always prefix the directory or filename with the drive specification (e.g. c:/xxx) using Unix directory name separators (forward slash). The drive letter itself can be upper or lower case (e.g. c:/xxx or C:/xxx).
Bacula's default for processing directories is to recursively descend in the directory saving all files and subdirectories. Bacula will not by default cross filesystems (or mount points in Unix parlance). This means that if you specify the root partition (e.g. /), Bacula will save only the root partition and not any of the other mounted filesystems. Similarly on Windows systems, you must explicitly specify each of the drives you want saved (e.g. c:/ and d:/ ...). In addition, at least for Windows systems, you will most likely want to enclose each specification within double quotes particularly if the directory (or file) name contains spaces. The df command on Unix systems will show you which mount points you must specify to save everything. See below for an example.
Take special care not to include a directory twice or Bacula will backup the same files two times wasting a lot of space on your archive device. Including a directory twice is very easy to do. For example:
Include {
Options {compression=GZIP }
File = /
File = /usr
}
on a Unix system where /usr is a subdirectory (rather than a mounted filesystem) will cause /usr to be backed up twice.
Please take note of the following items in the FileSet syntax:
- There is no equal sign (=) after the Include and before the opening brace ({). The same is true for the Exclude.
- Each directory (or filename) to be included or excluded is preceded by a File =. Previously they were simply listed on separate lines.
- The options that previously appeared on the Include line now must be specified within their own Options resource.
- The Exclude resource does not accept Options.
- When using wild-cards or regular expressions, directory names are always terminated with a slash (/) and filenames have no trailing slash.
The Options resource is optional, but when specified, it will contain a list of keyword=value options to be applied to the file-list. See below for the definition of file-list. Multiple Options resources may be specified one after another. As the files are found in the specified directories, the Options will applied to the filenames to determine if and how the file should be backed up. The wildcard and regular expression pattern matching parts of the Options resources are checked in the order they are specified in the FileSet until the first one that matches. Once one matches, the compression and other flags within the Options specification will apply to the pattern matched.
A key point is that in the absence of an Option or no other Option is matched, every file is accepted for backing up. This means that if you want to exclude something, you must explicitly specify an Option with an exclude = yes and some pattern matching.
Once Bacula determines that the Options resource matches the file under consideration, that file will be saved without looking at any other Options resources that may be present. This means that any wild cards must appear before an Options resource without wild cards.
If for some reason, Bacula checks all the Options resources to a file under consideration for backup, but there are no matches (generally because of wild cards that don't match), Bacula as a default will then backup the file. This is quite logical if you consider the case of no Options clause is specified, where you want everything to be backed up, and it is important to keep in mind when excluding as mentioned above.
However, one additional point is that in the case that no match was found, Bacula will use the options found in the last Options resource. As a consequence, if you want a particular set of “default” options, you should put them in an Options resource after any other Options.
It is a good idea to put all your wild-card and regex expressions inside double quotes to prevent conf file scanning problems.
This is perhaps a bit overwhelming, so there are a number of examples included below to illustrate how this works.
You find yourself using a lot of Regex statements, which will cost quite a lot of CPU time, we recommend you simplify them if you can, or better yet convert them to Wild statements which are much more efficient.
The directives within an Options resource may be one of the following:
- compression=GZIP
- All files saved will be software compressed using the GNU ZIP compression format. The compression is done on a file by file basis by the File daemon. If there is a problem reading the tape in a single record of a file, it will at most affect that file and none of the other files on the tape. Normally this option is not needed if you have a modern tape drive as the drive will do its own compression. In fact, if you specify software compression at the same time you have hardware compression turned on, your files may actually take more space on the volume.
Software compression is very important if you are writing your Volumes to a file, and it can also be helpful if you have a fast computer but a slow network, otherwise it is generally better to rely your tape drive's hardware compression. As noted above, it is not generally a good idea to do both software and hardware compression.
Specifying GZIP uses the default compression level 6 (i.e. GZIP is identical to GZIP6). If you want a different compression level (1 through 9), you can specify it by appending the level number with no intervening spaces to GZIP. Thus compression=GZIP1 would give minimum compression but the fastest algorithm, and compression=GZIP9 would give the highest level of compression, but requires more computation. According to the GZIP documentation, compression levels greater than six generally give very little extra compression and are rather CPU intensive.
You can overwrite this option per Storage resource with AllowCompression option.
- compression=LZO
- All files saved will be software compressed using the LZO compression format. The compression is done on a file by file basis by the File daemon. Everything else about GZIP is true for LZO.
LZO provides much faster compression and decompression speed but lower compression ratio than GZIP. If your CPU is fast enough you should be able to compress your data without making the backup duration longer.
Note that bacula only use one compression level LZO1X-1 specified by LZO.
You can overwrite this option per Storage resource with AllowCompression option.
- compression=ZSTD
- All files saved will be software compressed using the ZSTD compression format. The compression is done on a file by file basis by the File daemon. Everything else about GZIP is true for ZSTD.
ZSTD provides much faster compression and decompression speed but lower compression ratio than GZIP. If your CPU is fast enough you should be able to compress your data without making the backup duration longer.
You can overwrite this option per Storage resource with AllowCompression option.
- signature=SHA1
- An SHA1 signature will be computed for all The SHA1 algorithm is purported to be some what slower than the MD5 algorithm, but at the same time is significantly better from a cryptographic point of view (i.e. much fewer collisions, much lower probability of being hacked.) It adds four more bytes than the MD5 signature. We strongly recommend that either this option or MD5 be specified as a default for all files. Note, only one of the two options MD5 or SHA1 can be computed for any file.
- signature=SHA256
- A SHA256 signature will be computed for all files saved. Adding this option generates about 5% extra overhead for each file saved. In addition to the additional CPU time, the SHA256 signature adds 44 more bytes per file to your catalog.
- signature=SHA512
- A SHA256 signature will be computed for all files saved. Adding this option generates about 5% extra overhead for each file saved. In addition to the additional CPU time, the SHA512 signature adds 87 more bytes per file to your catalog.
- signature=MD5
- An MD5 signature will be computed for all files saved. Adding this option generates about 5% extra overhead for each file saved. In addition to the additional CPU time, the MD5 signature adds 16 more bytes per file to your catalog. We strongly recommend that this option or the SHA1 option be specified as a default for all files.
- signature=XXHASH
- An XXHASH signature will be computed for all files saved.
- dedup=none|storage|bothsides
- The Dedup Fileset option can use the following values:
- *
- storage All the deduplication work is done on Storage Daemon side if the device type is dedup. (Default value)
- none Force File Daemon and Storage Daemon to not use deduplication even if the device type is dedup.
- bothsides The deduplication work is done on the FD and the SD if the device type is dedup.
- basejob=<options>
-
The options letters specified are used when running a Backup Level=Full with BaseJobs. The options letters are the same as in the accurate= option below.
- accurate=<options>
- The options letters specified are used when running a Backup Level=Incremental/Differential in Accurate mode. The options letters are the same as in the verify= option below with the addition of the following options:
- A
- Always backup files
- M
- Look mtime/ctime like normal incremental backup
- o
- Save only the metadata of a file when possiblenoteAvailable from version 13.0.0 .
The 'o' option should be used in conjunction with one of the signature checking options (1, 2, 3, or 5). When the option is specified, the signature is computed only for files that have one of the other accurate options specified triggering a backup of the file (for example an inode change, a permission change, etc...). In cases where only the file's metadata has changed (ie: the signature is identical), only the file's attributes will be backed up. If the file's data has been changed (hence a different singature), the file will be backed up in the usual way
- verify=<options>
- The options letters specified are used when running a Verify Level=Catalog as well as the DiskToCatalog level job. The options letters may be any combination of the following:
- i
- compare the inodes
- p
- compare the permission bits
- n
- compare the number of links
- u
- compare the user id
- g
- compare the group id
- s
- compare the size
- a
- compare the access time
- m
- compare the modification time (st_mtime)
- c
- compare the change time (st_ctime)
- d
- report file size decreases
- 5
- compare the MD5 signature
- 1
- compare the SHA1 signature
- 2
- compare the SHA256 signature
- 3
- compare the SHA512 signature
A useful set of general options on the Level=Catalog or Level=DiskToCatalog verify is pins5 i.e. compare permission bits, then inodes, number of links, size, and finally MD5 changes.
To save some space when backing up files which have only metadata part changed (e.g. changed permissions) the 'pino5' options could be used (or some other combination with the 'o' flag). It will then compare permision bits, inotes, number of links and if any of it changes it will also compute file's singature to verify if only metadata need to be backed up or is it needed to update file's contents.
- onefs=<yes|no>
- If set to yes (the default), Bacula will remain on a single file system. That is it will not backup file systems that are mounted on a subdirectory. If you are using a *nix system, you may not even be aware that there are several different filesystems as they are often automatically mounted by the OS (e.g. /dev, /net, /sys, /proc, ...). With Bacula 1.38.0 or later, it will inform you when it decides not to traverse into another filesystem. This can be very useful if you forgot to backup a particular partition. An example of the informational message in the job report is:
rufus-fd: /misc is a different filesystem. Will not descend from / into /misc rufus-fd: /net is a different filesystem. Will not descend from / into /net rufus-fd: /var/lib/nfs/rpc_pipefs is a different filesystem. Will not descend from /var/lib/nfs into /var/lib/nfs/rpc_pipefs rufus-fd: /selinux is a different filesystem. Will not descend from / into /selinux rufus-fd: /sys is a different filesystem. Will not descend from / into /sys rufus-fd: /dev is a different filesystem. Will not descend from / into /dev rufus-fd: /home is a different filesystem. Will not descend from / into /home
Note: in older versions of Bacula, the above message was of the form:
Filesystem change prohibited. Will not descend into /misc
If you wish to backup multiple filesystems, you can explicitly list each filesystem you want saved. Otherwise, if you set the onefs option to no, Bacula will backup all mounted file systems (i.e. traverse mount points) that are found within the FileSet. Thus if you have NFS or Samba file systems mounted on a directory listed in your FileSet, they will also be backed up. Normally, it is preferable to set onefs=yes and to explicitly name each filesystem you want backed up. Explicitly naming the filesystems you want backed up avoids the possibility of getting into a infinite loop recursing filesystems. Another possibility is to use onefs=no and to set fstype=ext2, .... See the example below for more details.
If you think that Bacula should be backing up a particular directory and it is not, and you have onefs=no set, before you complain, please do:
stat / stat <filesystem>
where you replace filesystem with the one in question. If the Device: number is different for / and for your filesystem, then they are on different filesystems. E.g.
stat / File: `/' Size: 4096 Blocks: 16 IO Block: 4096 directory Device: 302h/770d Inode: 2 Links: 26 Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2005-11-10 12:28:01.000000000 +0100 Modify: 2005-09-27 17:52:32.000000000 +0200 Change: 2005-09-27 17:52:32.000000000 +0200 stat /net File: `/home' Size: 4096 Blocks: 16 IO Block: 4096 directory Device: 308h/776d Inode: 2 Links: 7 Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2005-11-10 12:28:02.000000000 +0100 Modify: 2005-11-06 12:36:48.000000000 +0100 Change: 2005-11-06 12:36:48.000000000 +0100
Also be aware that even if you include /home in your list of files to backup, as you most likely should, you will get the informational message that “/home is a different filesystem” when Bacula is processing the / directory. This message does not indicate an error. This message means that while examining the File = referred to in the second part of the message, Bacula will not descend into the directory mentioned in the first part of the message. However, it is possible that the separate filesystem will be backed up despite the message. For example, consider the following FileSet:
File = / File = /var
where /var is a separate filesystem. In this example, you will get a message saying that Bacula will not decend from / into /var. But it is important to realise that Bacula will descend into /var from the second File directive shown above. In effect, the warning is bogus, but it is supplied to alert you to possible omissions from your FileSet. In this example, /var will be backed up. If you changed the FileSet such that it did not specify /var, then /var will not be backed up.
- honor nodump flag=<yes|no>
- If your file system supports the nodump flag (e. g. most BSD-derived systems) Bacula will honor the setting of the flag when this option is set to yes. Files having this flag set will not be included in the backup and will not show up in the catalog. For directories with the nodump flag set recursion is turned off and the directory will be listed in the catalog. If the honor nodump flag option is not defined or set to no every file and directory will be eligible for backup.
- portable=<yes|no>
- If set to yes (default is no), the Bacula File daemon will backup Win32 files in a portable format, but not all Win32 file attributes will be saved and restored. By default, this option is set to no, which means that on Win32 systems, the data will be backed up using Windows BackupRead API calls and all the security and ownership attributes will be properly backed up (and restored). However this format is not portable to other systems - e.g. Unix, Win95/98/Me. When backing up Unix systems, this option is ignored, and unless you have a specific need to have portable backups, we recommend accept the default (no) so that the maximum information concerning your Windows files is saved.
- recurse=<yes|no>
- If set to yes (the default), Bacula will recurse (or descend) into all subdirectories found unless the directory is explicitly excluded using an exclude definition. If you set recurse=no, Bacula will save the subdirectory entries, but not descend into the subdirectories, and thus will not save the files or directories contained in the subdirectories. Normally, you will want the default (yes).
- sparse=<yes|no>
- Enable special code that checks for sparse files such as created by ndbm. The default is no, so no checks are made for sparse files. You may specify sparse=yes even on files that are not sparse file. No harm will be done, but there will be a small additional overhead to check for buffers of all zero, and if there is a 32K block of all zeros (see below), that block will become a hole in the file, which may not be desirable if the original file was not a sparse file.
Restrictions: Bacula reads files in 64K buffers. If the whole buffer is zero, it will be treated as a sparse block and not written to tape. However, if any part of the buffer is non-zero, the whole buffer will be written to tape, possibly including some disk sectors (generally 4098 bytes) that are all zero. As a consequence, Bacula's detection of sparse blocks is in 64K increments rather than the system block size. If anyone considers this to be a real problem, please send in a request for change with the reason.
If you are not familiar with sparse files, an example is say a file where you wrote 512 bytes at address zero, then 512 bytes at address 1 million. The operating system will allocate only two blocks, and the empty space or hole will have nothing allocated. However, when you read the sparse file and read the addresses where nothing was written, the OS will return all zeros as if the space were allocated, and if you backup such a file, a lot of space will be used to write zeros to the volume. Worse yet, when you restore the file, all the previously empty space will now be allocated using much more disk space. By turning on the sparse option, Bacula will specifically look for empty space in the file, and any empty space will not be written to the Volume, nor will it be restored. The price to pay for this is that Bacula must search each block it reads before writing it. On a slow system, this may be important. If you suspect you have sparse files, you should benchmark the difference or set sparse for only those files that are really sparse.
You probably should not use this option on files or raw disk devices that are not really sparse files (i.e. have holes in them).
- readfifo=<yes|no>
- If enabled, tells the Client to read the data on a backup and write the data on a restore to any FIFO (pipe) that is explicitly mentioned in the FileSet. In this case, you must have a program already running that writes into the FIFO for a backup or reads from the FIFO on a restore. This can be accomplished with the RunBeforeJob directive. If this is not the case, Bacula will hang indefinitely on reading/writing the FIFO. When this is not enabled (no, the default), the Client simply saves the directory entry for the FIFO.
Unfortunately, when Bacula runs a RunBeforeJob, it waits until that script terminates, and if the script accesses the FIFO to write into the it, the Bacula job will block and everything will stall. However, Vladimir Stavrinov as supplied tip that allows this feature to work correctly. He simply adds the following to the beginning of the RunBeforeJob script:
exec > /dev/null
- noatime=<yes|no>
- If enabled, and if your Operating System supports the O_NOATIME file open flag, Bacula will open all files to be backed up with this option. It makes it possible to read a file without updating the inode atime (and also without the inode ctime update which happens if you try to set the atime back to its previous value). It also prevents a race condition when two programs are reading the same file, but only one does not want to change the atime. It's most useful for backup programs and file integrity checkers (and bacula can fit on both categories).
This option is particularly useful for sites where users are sensitive to their MailBox file access time. It replaces both the keepatime option without the inconveniences of that option (see below).
If your Operating System does not support this option, it will be silently ignored by Bacula.
- mtimeonly=<yes|no>
- If enabled, tells the Client that the selection of files during Incremental and Differential backups should based only on the st_mtime value in the stat() packet. The default is no which means that the selection of files to be backed up will be based on both the st_mtime and the st_ctime values. In general, it is not recommended to use this option.
- keepatime=<yes|no>
- The default is no. When enabled, Bacula will reset the st_atime (access time) field of files that it backs up to their value prior to the backup. This option is not generally recommended as there are very few programs that use st_atime, and the backup overhead is increased because of the additional system call necessary to reset the times. However, for some files, such as mailboxes, when Bacula backs up the file, the user will notice that someone (Bacula) has accessed the file. In this, case keepatime can be useful. (I'm not sure this works on Win32).
Note, if you use this feature, when Bacula resets the access time, the change time (st_ctime) will automatically be modified by the system, so on the next incremental job, the file will be backed up even if it has not changed. As a consequence, you will probably also want to use mtimeonly = yes as well as keepatime (thanks to Rudolf Cejka for this tip).
- checkfilechanges=<yes|no>
- If enabled, the Client will check size, age of each file after their backup to see if they have changed during backup. If time or size mismatch, an error will raise. The default value is yes.
zog-fd: Client1.2007-03-31_09.46.21 Error: /tmp/test mtime changed during backup.
In general, it is recommended to use this option to backup regular files. It is not compatible with fifo or plugin streams.
- hardlinks=<yes|no>
- When enabled (yes, the default), this directive will cause hard links to be backed up. However, the File daemon keeps track of hard linked files and will backup the data only once. The process of keeping track of the hard links can be quite expensive if you have lots of them (tens of thousands or more). This doesn't occur on normal Unix systems, but if you use a program like BackupPC, it can create hundreds of thousands, or even millions of hard links. Backups become very long and the File daemon will consume a lot of CPU power checking hard links. In such a case, set hardlinks=no and hard links will not be backed up. Note, using this option will most likely backup more data and on a restore the file system will not be restored identically to the original.
- wild=<string>
- Specifies a wild-card string to be applied to the filenames and directory names. Note, if Exclude is not enabled, the wild-card will select which files are to be included. If Exclude=yes is specified, the wild-card will select which files are to be excluded. Multiple wild-card directives may be specified, and they will be applied in turn until the first one that matches. Note, if you exclude a directory, no files or directories below it will be matched.
You may want to test your expressions prior to running your backup by using the bwild program. Please see the Utilities chapter of the Bacula Enterprise Utility Programs manual for more information. You can also test your full FileSet definition by using the estimate command in the Bacula Enterprise Console manual.It is recommended to enclose the string in double quotes.
- enhancedwild=<yes|no>
- The Enhanced Wild directive controls how path name matching with wildcards is done.
The default is no, which makes wildcards not match match path separators. If set to yes, an asterisk, question mark, or a bracketed slash will also be matched by a slash. In other words, wildcards will then span path hierarchy.
- wilddir=<string>
- Specifies a wild-card string to be applied to directory names only. No filenames will be matched by this directive. Note, if Exclude is not enabled, the wild-card will select directories to be included. If Exclude=yes is specified, the wild-card will select which directories are to be excluded. Multiple wild-card directives may be specified, and they will be applied in turn until the first one that matches. Note, if you exclude a directory, no files or directories below it will be matched.
It is recommended to enclose the string in double quotes.
You may want to test your expressions prior to running your backup by using the bwild program. Please see the Utilities chapter of the Bacula Enterprise Utility Programs manual for more information. You can also test your full FileSet definition by using the estimate command in the Bacula Enterprise Console manual.An example of excluding with the WildDir option on Win32 machines is presented below.
- wildfile=<string>
- Specifies a wild-card string to be applied to non-directories. That is no directory entries will be matched by this directive. However, note that the match is done against the full path and filename, so your wild-card string must take into account that filenames are preceded by the full path. If Exclude is not enabled, the wild-card will select which files are to be included. If Exclude=yes is specified, the wild-card will select which files are to be excluded. Multiple wild-card directives may be specified, and they will be applied in turn until the first one that matches.
It is recommended to enclose the string in double quotes.
You may want to test your expressions prior to running your backup by using the bwild program. Please see the Utilities chapter of the Bacula Enterprise Utility Programs manual for more information. You can also test your full FileSet definition by using the estimate command in the Bacula Enterprise Console manual.An example of excluding with the WildFile option on Win32 machines is presented below.
- regex=<string>
- Specifies a POSIX extended regular expression to be applied to the filenames and directory names, which include the full path. If Exclude is not enabled, the regex will select which files are to be included. If Exclude=yes is specified, the regex will select which files are to be excluded. Multiple regex directives may be specified within an Options resource, and they will be applied in turn until the first one that matches. Note, if you exclude a directory, no files or directories below it will be matched.
It is recommended to enclose the string in double quotes.
The regex libraries differ from one operating system to another, and in addition, regular expressions are complicated, so you may want to test your expressions prior to running your backup by using the bregex program. Please see the Utilities chapter of the Bacula Enterprise Utility Programs manual for more information. You can also test your full FileSet definition by using the estimate command in the Bacula Enterprise Console manual.
You find yourself using a lot of Regex statements, which will cost quite a lot of CPU time, we recommend you simplify them if you can, or better yet convert them to Wild statements which are much more efficient.
- regexfile=<string>
- Specifies a POSIX extended regular expression to be applied to non-directories. No directories will be matched by this directive. However, note that the match is done against the full path and filename, so your regex string must take into account that filenames are preceded by the full path. If Exclude is not enabled, the regex will select which files are to be included. If Exclude=yes is specified, the regex will select which files are to be excluded. Multiple regex directives may be specified, and they will be applied in turn until the first one that matches.
It is recommended to enclose the string in double quotes.
The regex libraries differ from one operating system to another, and in addition, regular expressions are complicated, so you may want to test your expressions prior to running your backup by using the bregex program. Please see the bregex command of the Bacula Enterprise Utility Programs manual more.
- regexdir=<string>
- Specifies a POSIX extended regular expression to be applied to directory names only. No filenames will be matched by this directive. Note, if Exclude is not enabled, the regex will select directories files are to be included. If Exclude=yes is specified, the regex will select which files are to be excluded. Multiple regex directives may be specified, and they will be applied in turn until the first one that matches. Note, if you exclude a directory, no files or directories below it will be matched.
It is recommended to enclose the string in double quotes.
The regex libraries differ from one operating system to another, and in addition, regular expressions are complicated, so you may want to test your expressions prior to running your backup by using the bregex program. Please see the bregex command of the Bacula Enterprise Utility Programs manual more.
- exclude=<yes|no>
- The default is no. When enabled, any files matched within the Options will be excluded from the backup.
- aclsupport=<yes|no>
- The default is no. If this option is set to yes, and you have the POSIX libacl installed on your Linux system, Bacula will backup the file and directory Unix Access Control Lists (ACLs) as defined in IEEE Std 1003.1e draft 17 and “POSIX.1e” (abandoned). This feature is available on Unix systems only and requires the Linux ACL library. Bacula is automatically compiled with ACL support if the libacl library is installed on your Linux system (shown in config.out). While restoring the files Bacula will try to restore the ACLs, if there is no ACL support available on the system, Bacula restores the files and directories but not the ACL information. Please note, if you backup an EXT3 or XFS filesystem with ACLs, then you restore them to a different filesystem (perhaps reiserfs) that does not have ACLs, the ACLs will be ignored.
For other operating systems there is support for either POSIX ACLs or the more extensible NFSv4 ACLs.
The ACL stream format between Operation Systems is not compatible so for example an ACL saved on Linux cannot be restored on Solaris.
The following Operating Systems are currently supported:
- AIX (pre-5.3 (POSIX) and post 5.3 (POSIX and NFSv4) ACLs)
- Darwin
- FreeBSD (POSIX and NFSv4/ZFS ACLs)
- HPUX
- IRIX
- Linux (POSIX and GPFS)
- Solaris (POSIX and NFSv4/ZFS ACLs)
- Tru64
- xattrsupport=<yes|no>
- The default is no. If this option is set to yes, and your operating system support either so called Extended Attributes or Extensible Attributes Bacula will backup the file and directory XATTR data. This feature is available on UNIX only and depends on support of some specific library calls in libc.
The XATTR stream format between Operating Systems is not compatible so an XATTR saved on Linux cannot for example be restored on Solaris.
On some operating systems ACLs are also stored as Extended Attributes (Linux, Darwin, FreeBSD) Bacula checks if you have the aclsupport option enabled and if so will not save the same info when saving extended attribute information. Thus ACLs are only saved once.
The following Operating Systems are currently supported:
- AIX (Extended Attributes)
- Darwin (Extended Attributes)
- FreeBSD (Extended Attributes)
- IRIX (Extended Attributes)
- Linux (Extended Attributes)
- NetBSD (Extended Attributes)
- Solaris (Extended Attributes and Extensible Attributes)
- Tru64 (Extended Attributes)
- ignore case=<yes|no>
- The default is no. On Windows systems, you will almost surely want to set this to yes. When this directive is set to yes all the case of character will be ignored in wild-card and regex comparisons. That is an uppercase A will match a lowercase a.
- fstype=filesystem-type-list
- This option ensures that the FD, while processing files with this option block effective, will only descend into filesystems of types mentioned in the Filesystem-type-list. This is most useful in combination with One FS = no set.
This directive may appear multiple times, and all list elements will be added, i.e. a specification of
FS Type = ext2, xfs FS Type = msdos
will result in all three mentioned file system types being accepted.On Windows, this functionality is not available, but see “Drive Type” above ((here)).
- DriveType=Windows-drive-type
- This option is effective only on Windows machines and is somewhat similar to the Unix/Linux fstype described above, except that it allows you to select what Windows drive types you want to allow. By default all drive types are accepted.
The permitted drivetype names are:
removable, fixed, remote, cdrom, ramdisk
You may have multiple Driveype directives, and thus permit matching of multiple drive types within a single Options resource. If the type specified on the drivetype directive does not match the filesystem for a particular directive, that directory will not be backed up. This directive can be used to prevent backing up non-local filesystems. Normally, when you use this directive, you would also set onefs=no so that Bacula will traverse filesystems.
This option is not implemented in Unix/Linux systems.
- hfsplussupport=<yes|no>
- This option allows you to turn on support for Mac OSX HFS plus finder information.
- strippath=<integer>
- This option will cause integer paths to be stripped from the front of the full path/filename being backed up. This can be useful if you are migrating data from another vendor or if you have taken a snapshot into some subdirectory. This directive can cause your filenames to be overlayed with regular backup data, so should be used only by experts and with great care.
<file-list> is a list of directory and/or filename names specified with a File = directive. To include names containing spaces, enclose the name between double-quotes. Wild-cards are not interpreted in file-lists. They can only be specified in Options resources.
There are a number of special cases when specifying directories and files in a file-list. They are:
- Any name preceded by an at-sign (@) is assumed to be the name of a file, which contains a list of files each preceded by a “File =”. The named file is read once when the configuration file is parsed during the Director startup. Note, that the file is read on the Director's machine and not on the Client's. In fact, the @filename can appear anywhere within the conf file where a token would be read, and the contents of the named file will be logically inserted in the place of the @filename. What must be in the file depends on the location the @filename is specified in the conf file. For example:
Include { Options {compression=GZIP } @/home/files/my-files } - Any name beginning with a vertical bar (|) is assumed to be the name of a program. This program will be executed on the Director's machine at the time the Job starts (not when the Director reads the configuration file), and any output from that program will be assumed to be a list of files or directories, one per line, to be included. Before submitting the specified command bacula will performe character substitution.
This allows you to have a job that, for example, includes all the local partitions even if you change the partitioning by adding a disk. The examples below show you how to do this. However, please note two things:
- if you want the local filesystems, you probably should be using the new fstype directive, which was added in version 1.36.3 and set onefs=no.
- the exact syntax of the command needed in the examples below is very system dependent. For example, on recent Linux systems, you may need to add the -P option, on FreeBSD systems, the options will be different as well.
As an example:
Include { Options {signature = SHA1 } File = "|sh -c 'df -l | grep \"^/dev/hd[ab]\" | grep -v \".*/tmp\" \ | awk \"{print \\$6}\"'" }will produce a list of all the local partitions on a Red Hat Linux system. Note, the above line was split, but should normally be written on one line. Quoting is a real problem because you must quote for Bacula which consists of preceding every \ and every " with a \, and you must also quote for the shell command. In the end, it is probably easier just to execute a small file with:
Include { Options { signature=MD5 } File = "|my_partitions" }where my_partitions has:
#!/bin/sh df -l | grep "^/dev/hd[ab]" | grep -v ".*/tmp" \ | awk "{print \$6}"If the vertical bar (|) in front of my_partitions is preceded by a backslash as in
\|, the program will be executed on the Client's machine instead of on the Director's machine. Please note that if the filename is given within quotes, you will need to use two slashes. An example, provided by John Donagher, that backs up all the local UFS partitions on a remote system is:FileSet { Name = "All local partitions" Include { Options {signature=SHA1; onefs=yes; } File = "\\|bash -c \"df -klF ufs | tail +2 | awk '{print \$6}'\"" } }The above requires two backslash characters after the double quote (one preserves the next one). If you are a Linux user, just change the ufs to ext3 (or your preferred filesystem type), and you will be in business.
If you know what filesystems you have mounted on your system, e.g. for Red Hat Linux normally only ext2 and ext3, you can backup all local filesystems using something like:
Include { Options {signature = SHA1; onfs=no; fstype=ext2 } File = / }On Windows, the command is executed with “cmd /c” prefix, and it is recommended to keep the path of the scripts as simple as possible (without spaces for example). The exact escaping sequence of the string can be difficult to determine.
- Any file-list item preceded by a less-than sign (<) will be taken to be a file. This file will be read on the Director's machine (see below for doing it on the Client machine) at the time the Job starts, and the data will be assumed to be a list of directories or files, one per line, to be included. The names should start in column 1 and should not be quoted even if they contain spaces. This feature allows you to modify the external file and change what will be saved without stopping and restarting Bacula as would be necessary if using the @ modifier noted above. For example:
Include { Options {signature = SHA1 } File = "</home/files/local-filelist" }If you precede the less-than sign (<) with a backslash as in
\<, the file-list will be read on the Client machine instead of on the Director's machine. Please note that if the filename is given within quotes, you will need to use two slashes.Include { Options {signature = SHA1 } File = "\\</home/xxx/filelist-on-client" } - If you explicitly specify a block device such as /dev/hda1, then Bacula (starting with version 1.28) will assume that this is a raw partition to be backed up. In this case, you are strongly urged to specify a sparse=yes include option, otherwise, you will save the whole partition rather than just the actual data that the partition contains. For example:
Include { Options {signature=MD5; sparse=yes } File = /dev/hd6 }will backup the data in device /dev/hd6. Note, the /dev/hd6 must be the raw partition itself. Bacula will not back it up as a raw device if you specify a symbolic link to a raw device such as my be created by the LVM Snapshot utilities.
Ludovic Strappazon has pointed out that this feature can be used to backup a full Microsoft Windows disk. Simply boot into the system using a Linux Rescue disk, then load a statically linked Bacula as described in the Disaster Recovery Using Bacula chapter of this manual. Then save the whole disk partition. In the case of a disaster, you can then restore the desired partition by again booting with the rescue disk and doing a restore of the partition.
- If you explicitly specify a FIFO device name (created with mkfifo), and you add the option readfifo=yes as an option, Bacula will read the FIFO and back its data up to the Volume. For example:
Include { Options { signature=SHA1 readfifo=yes } File = /home/abc/fifo }if /home/abc/fifo is a fifo device, Bacula will open the fifo, read it, and store all data thus obtained on the Volume. Please note, you must have a process on the system that is writing into the fifo, or Bacula will hang, and after one minute of waiting, Bacula will give up and go on to the next file. The data read can be anything since Bacula treats it as a stream.
This feature can be an excellent way to do a “hot” backup of a very large database. You can use the RunBeforeJob to create the fifo and to start a program that dynamically reads your database and writes it to the fifo. Bacula will then write it to the Volume. Be sure to read the readfifo section that gives a tip to ensure that the RunBeforeJob does not block Bacula.
During the restore operation, the inverse is true, after Bacula creates the fifo if there was any data stored with it (no need to explicitly list it or add any options), that data will be written back to the fifo. As a consequence, if any such FIFOs exist in the fileset to be restored, you must ensure that there is a reader program or Bacula will block, and after one minute, Bacula will time out the write to the fifo and move on to the next file.
- A file-list may not contain wild-cards. Use directives in the Options resource if you wish to specify wild-cards or regular expression matching.
- The ExcludeDirContaining = <filename> is a directive that can be added to the Include section of the FileSet resource. If the specified filename (filename-string) is found on the Client in any directory to be backed up, the whole directory will be ignored (not backed up). For example:
# List of files to be backed up FileSet { Name = "MyFileSet" Include { Options { signature = MD5 } File = /home Exclude Dir Containing = .excludeme } }But in /home, there may be hundreds of directories of users and some people want to indicate that they don't want to have certain directories backed up. For example, with the above FileSet, if the user or sysadmin creates a file named .excludeme in specific directories, such as
/home/user/www/cache/.excludeme /home/user/temp/.excludeme
then Bacula will not backup the two directories named:
/home/user/www/cache /home/user/temp
NOTE: subdirectories will not be backed up. That is, the directive applies to the two directories in question and any children (be they files, directories, etc).
FileSet Examples
The following is an example of a valid FileSet resource definition. Note, the first Include pulls in the contents of the file /etc/backup.list when Bacula is started (i.e. the @), and that file must have each filename to be backed up preceded by a File = and on a separate line.
FileSet {
Name = "Full Set"
Include {
Options {
Compression=GZIP
signature=SHA1
Sparse = yes
}
@/etc/backup.list
}
Include {
Options {
wildfile = "*.o"
wildfile = "*.exe"
Exclude = yes
}
File = /root/myfile
File = /usr/lib/another_file
}
}
In the above example, all the files contained in /etc/backup.list will be compressed with GZIP compression, an SHA1 signature will be computed on the file's contents (its data), and sparse file handling will apply.
The two directories /root/myfile and /usr/lib/another_file will also be saved without any options, but all files in those directories with the extensions .o and .exe will be excluded.
Let's say that you now want to exclude the directory /tmp. The simplest way to do so is to add an Exclude directive that lists /tmp. The example above would then become:
FileSet {
Name = "Full Set"
Include {
Options {
Compression=GZIP
signature=SHA1
Sparse = yes
}
@/etc/backup.list
}
Include {
Options {
wildfile = "*.o"
wildfile = "*.exe"
Exclude = yes
}
File = /root/myfile
File = /usr/lib/another_file
}
Exclude {
File = /tmp # don't add trailing /
}
}
You can add wild-cards to the File directives listed in the Exclude directive, but you need to take care because if you exclude a directory, it and all files and directories below it will also be excluded.
Now let's make a slight variation on the above and suppose you want to save all your filesystems except /tmp. The problem that comes up is that Bacula will not normally cross from one filesystem to another. Doing a df command, you get the following output:
[kern@rufus k]$ df Filesystem 1k-blocks Used Available Use% Mounted on /dev/hda5 5044156 439232 4348692 10% / /dev/hda1 62193 4935 54047 9% /boot /dev/hda9 20161172 5524660 13612372 29% /home /dev/hda2 62217 6843 52161 12% /rescue /dev/hda8 5044156 42548 4745376 1% /tmp /dev/hda6 5044156 2613132 2174792 55% /usr none 127708 0 127708 0% /dev/shm //minimatou/c$ 14099200 9895424 4203776 71% /mnt/mmatou lmatou:/ 1554264 215884 1258056 15% /mnt/matou lmatou:/home 2478140 1589952 760072 68% /mnt/matou/home lmatou:/usr 1981000 1199960 678628 64% /mnt/matou/usr lpmatou:/ 995116 484112 459596 52% /mnt/pmatou lpmatou:/home 19222656 2787880 15458228 16% /mnt/pmatou/home lpmatou:/usr 2478140 2038764 311260 87% /mnt/pmatou/usr deuter:/ 4806936 97684 4465064 3% /mnt/deuter deuter:/home 4806904 280100 4282620 7% /mnt/deuter/home deuter:/files 44133352 27652876 14238608 67% /mnt/deuter/files
And we see that there are a number of separate filesystems (/ /boot /home /rescue /tmp and /usr not to mention mounted systems). If you specify only / in your Include list, Bacula will only save the Filesystem /dev/hda5. To save all filesystems except /tmp with out including any of the Samba or NFS mounted systems, and explicitly excluding a /tmp, /proc, .journal, and .autofsck, which you will not want to be saved and restored, you can use the following:
FileSet {
Name = Include_example
Include {
Options {
wilddir = /proc
wilddir = /tmp
wildfile = "/.journal"
wildfile = "/.autofsck"
exclude = yes
}
File = /
File = /boot
File = /home
File = /rescue
File = /usr
}
}
Since /tmp is on its own filesystem and it was not explicitly named in the Include list, it is not really needed in the exclude list. It is better to list it in the Exclude list for clarity, and in case the disks are changed so that it is no longer in its own partition.
Now, lets assume you only want to backup .Z and .gz files and nothing else. This is a bit trickier because Bacula by default will select everything to backup, so we must exclude everything but .Z and .gz files. If we take the first example above and make the obvious modifications to it, we might come up with a FileSet that looks like this:
FileSet {
Name = "Full Set"
Include { !!!!!!!!!!!!
Options { This
wildfile = "*.Z" example
wildfile = "*.gz" doesn't
work
} !!!!!!!!!!!!
File = /myfile
}
}
The *.Z and *.gz files will indeed be backed up, but all other files that are not matched by the Options directives will automatically be backed up too (i.e. that is the default rule).
To accomplish what we want, we must explicitly exclude all other files. We do this with the following:
FileSet {
Name = "Full Set"
Include {
Options {
wildfile = "*.Z"
wildfile = "*.gz"
}
Options {
Exclude = yes
RegexFile = ".*"
}
File = /myfile
}
}
The “trick” here was to add a RegexFile expression that matches all files. It does not match directory names, so all directories in /myfile will be backed up (the directory entry) and any *.Z and *.gz files contained in them. If you know that certain directories do not contain any *.Z or *.gz files and you do not want the directory entries backed up, you will need to explicitly exclude those directories. Backing up a directory entry is not very expensive.
Bacula uses the system regex library and some of them are different on different OSes. The above has been reported not to work on FreeBSD. This can be tested by using the estimate job=job-name listing command in the console and adapting the RegexFile expression appropriately. In a future version of Bacula, we will supply our own Regex code to avoid such system dependencies.
Please be aware that allowing Bacula to traverse or change file systems can be very dangerous. For example, with the following:
FileSet {
Name = "Bad example"
Include {
Options {onefs=no }
File = /mnt/matou
}
}
you will be backing up an NFS mounted partition (/mnt/matou), and since onefs is set to no, Bacula will traverse file systems. Now if /mnt/matou has the current machine's file systems mounted, as is often the case, you will get yourself into a recursive loop and the backup will never end.
As a final example, let's say that you have only one or two subdirectories of /home that you want to backup. For example, you want to backup only subdirectories beginning with the letter a and the letter b - i.e. /home/a* and /home/b*. Now, you might first try:
FileSet {
Name = "Full Set"
Include {
Options {
wilddir = "/home/a*"
wilddir = "/home/b*"
}
File = /home
}
}
The problem is that the above will include everything in /home. To get things to work correctly, you need to start with the idea of exclusion instead of inclusion. So, you could simply exclude all directories except the two you want to use:
FileSet {
Name = "Full Set"
Include {
Options {
RegexDir = "^/home/[c-z]"
exclude = yes
}
File = /home
}
}
And assuming that all subdirectories start with a lowercase letter, this would work.
An alternative would be to include the two subdirectories desired and exclude everything else:
FileSet {
Name = "Full Set"
Include {
Options {
wilddir = "/home/a*"
wilddir = "/home/b*"
}
Options {
RegexDir = ".*"
exclude = yes
}
File = /home
}
}
The following example shows how to back up only the My Pictures directory inside the My Documents directory for all users in C:/Documents and Settings, i.e. everything matching the pattern:
C:/Documents and Settings/*/My Documents/My Pictures/*
To understand how this can be achieved, there are two important points to remember:
Firstly, Bacula traverses the filesystem starting from the File = lines. It stops descending when a directory is excluded, so you must include all ancestor (higher level) directories of each directory containing files to be included.
Secondly, each directory and file is compared to the Options clauses in the order they appear in the FileSet. When a match is found, no further Optionss are compared and the directory or file is either included or excluded.
The FileSet resource definition below implements this by including specifc directories and files and excluding everything else.
FileSet {
Name = "AllPictures"
Include {
File = "C:/Documents and Settings"
Options {
signature = SHA1
verify = s1
IgnoreCase = yes
# Include all users' directories so we reach the inner ones. Unlike a
# WildDir pattern ending in *, this RegExDir only matches the top-level
# directories and not any inner ones.
RegExDir = "^C:/Documents and Settings/[^/]+$"
# Ditto all users' My Documents directories.
WildDir = "C:/Documents and Settings/*/My Documents"
# Ditto all users' My Documents/My Pictures directories.
WildDir = "C:/Documents and Settings/*/My Documents/My Pictures"
# Include the contents of the My Documents/My Pictures directories and
# any subdirectories.
Wild = "C:/Documents and Settings/*/My Documents/My Pictures/*"
}
Options {
Exclude = yes
IgnoreCase = yes
# Exclude everything else, in particular any files at the top level and
# any other directories or files in the users' directories.
Wild = "C:/Documents and Settings/*"
}
}
}
In the above example, we setup a FileSet to backup a subset of a single directory (on Windows) based on filename.
FileSet {
Name = "win-fileset"
Include {
Options {
signature = MD5
wildfile = "C:/File/backup_NDB_COUNT*"
}
# Exclude all files not matching the wildfile list above
Options {
Exclude = yes
RegexFile = ".*"
}
File = C:/File
}
}
Backing up Raw Partitions
The following FileSet definition will backup a raw partition:
FileSet {
Name = "RawPartition"
Include {
Options {sparse=yes }
File = /dev/hda2
}
}
While backing up and restoring a raw partition, you should ensure that no other process including the system is writing to that partition. As a precaution, you are strongly urged to ensure that the raw partition is not mounted or is mounted read-only. If necessary, this can be done using the RunBeforeJob directive.
Excluding Files and Directories
You may also include full filenames or directory names in addition to using wild-cards and Exclude=yes in the Options resource as specified above by simply including the files to be excluded in an Exclude resource within the FileSet. It accepts wild-cards pattern, so for a directory, don't add a trailing /. For example:
FileSet {
Name = Exclusion_example
Include {
Options {
Signature = SHA1
}
File = /
File = /boot
File = /home
File = /rescue
File = /usr
}
Exclude {
File = /proc
File = /tmp # Don't add trailing /
File = .journal
File = .autofsck
}
}
Windows FileSets
If you are entering Windows file names, the directory path may be preceded by the drive and a colon (as in c:). However, the path separators must be specified in Unix convention (i.e. forward slash (/)). If you wish to include a quote in a file name, precede the quote with a backslash (\). For example you might use the following for a Windows machine to backup the “My Documents” directory:
FileSet {
Name = "Windows Set"
Include {
Options {
WildFile = "*.obj"
WildFile = "*.exe"
exclude = yes
}
File = "c:/My Documents"
}
}
For exclude lists to work correctly on Windows, you must observe the following rules:
- Filenames are case sensitive, so you must use the correct case.
- To exclude a directory, you must not have a trailing slash on the directory name.
- If you have spaces in your filename, you must enclose the entire name in double-quote characters ("). Trying to use a backslash before the space will not work.
- If you are using the old Exclude syntax (noted below), you may not specify a drive letter in the exclude. The new syntax noted above should work fine including driver letters.
Thanks to Thiago Lima for summarizing the above items for us. If you are having difficulties getting includes or excludes to work, you might want to try using the estimate job=xxx listing command documented in the estimate command of Bacula Enterprise Console manual.
On Win32 systems, if you move a directory or file or rename a file into the set of files being backed up, and a Full backup has already been made, Bacula will not know there are new files to be saved during an Incremental or Differential backup (blame Microsoft, not me). To avoid this problem, please copy any new directory or files into the backup area. If you do not have enough disk to copy the directory or files, move them, but then initiate a Full backup.
A Windows Example FileSet
The following example was contributed by Russell Howe. Please note that for presentation purposes, the lines beginning with Data and Internet have been wrapped and should included on the previous line with one space.
This is my Windows 2000 fileset:
FileSet {
Name = "Windows 2000"
Include {
Options {
signature = MD5
Exclude = yes
IgnoreCase = yes
# Exclude Mozilla-based programs' file caches
WildDir = "[A-Z]:/Documents and Settings/*/Application
Data/*/Profiles/*/*/Cache"
WildDir = "[A-Z]:/Documents and Settings/*/Application
Data/*/Profiles/*/*/Cache.Trash"
WildDir = "[A-Z]:/Documents and Settings/*/Application
Data/*/Profiles/*/*/ImapMail"
# Exclude user's registry files - they're always in use anyway.
WildFile = "[A-Z]:/Documents and Settings/*/Local Settings/Application
Data/Microsoft/Windows/usrclass.*"
WildFile = "[A-Z]:/Documents and Settings/*/ntuser.*"
# Exclude directories full of lots and lots of useless little files
WildDir = "[A-Z]:/Documents and Settings/*/Cookies"
WildDir = "[A-Z]:/Documents and Settings/*/Recent"
WildDir = "[A-Z]:/Documents and Settings/*/Local Settings/History"
WildDir = "[A-Z]:/Documents and Settings/*/Local Settings/Temp"
WildDir = "[A-Z]:/Documents and Settings/*/Local Settings/Temporary
Internet Files"
# These are always open and unable to be backed up
WildFile = "[A-Z]:/Documents and Settings/All Users/Application
Data/Microsoft/Network/Downloader/qmgr[01].dat"
# Some random bits of Windows we want to ignore
WildFile = "[A-Z]:/WINNT/security/logs/scepol.log"
WildDir = "[A-Z]:/WINNT/system32/config"
WildDir = "[A-Z]:/WINNT/msdownld.tmp"
WildDir = "[A-Z]:/WINNT/Internet Logs"
WildDir = "[A-Z]:/WINNT/$Nt*Uninstall*"
WildDir = "[A-Z]:/WINNT/sysvol"
WildFile = "[A-Z]:/WINNT/cluster/CLUSDB"
WildFile = "[A-Z]:/WINNT/cluster/CLUSDB.LOG"
WildFile = "[A-Z]:/WINNT/NTDS/edb.log"
WildFile = "[A-Z]:/WINNT/NTDS/ntds.dit"
WildFile = "[A-Z]:/WINNT/NTDS/temp.edb"
WildFile = "[A-Z]:/WINNT/ntfrs/jet/log/edb.log"
WildFile = "[A-Z]:/WINNT/ntfrs/jet/ntfrs.jdb"
WildFile = "[A-Z]:/WINNT/ntfrs/jet/temp/tmp.edb"
WildFile = "[A-Z]:/WINNT/system32/CPL.CFG"
WildFile = "[A-Z]:/WINNT/system32/dhcp/dhcp.mdb"
WildFile = "[A-Z]:/WINNT/system32/dhcp/j50.log"
WildFile = "[A-Z]:/WINNT/system32/dhcp/tmp.edb"
WildFile = "[A-Z]:/WINNT/system32/LServer/edb.log"
WildFile = "[A-Z]:/WINNT/system32/LServer/TLSLic.edb"
WildFile = "[A-Z]:/WINNT/system32/LServer/tmp.edb"
WildFile = "[A-Z]:/WINNT/system32/wins/j50.log"
WildFile = "[A-Z]:/WINNT/system32/wins/wins.mdb"
WildFile = "[A-Z]:/WINNT/system32/wins/winstmp.mdb"
# Temporary directories & files
WildDir = "[A-Z]:/WINNT/Temp"
WildDir = "[A-Z]:/temp"
WildFile = "*.tmp"
WildDir = "[A-Z]:/tmp"
WildDir = "[A-Z]:/var/tmp"
# Recycle bins
WildDir = "[A-Z]:/RECYCLER"
# Swap files
WildFile = "[A-Z]:/pagefile.sys"
# These are programs and are easier to reinstall than restore from
# backup
WildDir = "[A-Z]:/cygwin"
WildDir = "[A-Z]:/Program Files/Grisoft"
WildDir = "[A-Z]:/Program Files/Java"
WildDir = "[A-Z]:/Program Files/Java Web Start"
WildDir = "[A-Z]:/Program Files/JavaSoft"
WildDir = "[A-Z]:/Program Files/Microsoft Office"
WildDir = "[A-Z]:/Program Files/Mozilla Firefox"
WildDir = "[A-Z]:/Program Files/Mozilla Thunderbird"
WildDir = "[A-Z]:/Program Files/mozilla.org"
WildDir = "[A-Z]:/Program Files/OpenOffice*"
}
# Our Win2k boxen all have C: and D: as the main hard drives.
File = "C:/"
File = "D:/"
}
}
Note, the three line of the above Exclude were split to fit on the document page, they should be written on a single line in real use.
Windows NTFS Naming Considerations
NTFS filenames containing Unicode characters should now be supported as of version 1.37.30 or later.
Testing Your FileSet
If you wish to get an idea of what your FileSet will really backup or if your exclusion rules will work correctly, you can test it by using the estimate command in the Console program. See the estimate command of Bacula Enterprise Console manual.
As an example, suppose you add the following test FileSet:
FileSet {
Name = Test
Include {
File = /home/xxx/test
Options {
regex = ".*\.c$"
}
}
}
You could then add some test files to the directory /home/xxx/test and use the following command in the console:
estimate job=<any-job-name> listing client=<desired-client> fileset=Test
to give you a listing of all files that match. In the above example, it should be only files with names ending in .c.
Include All Windows Drives in FileSet
The alldrives Windows Plugin allows you to include all local drives with a simple directive. This plugin is available in the Windows 64 and 32 bit installer.
FileSet {
Name = EverythingFS
...
Include {
Plugin = "alldrives"
}
}
You exclude some specific drives with the exclude option.
FileSet {
Name = EverythingFS
...
Include {
Plugin = "alldrives: exclude=D,E"
}
}
The alldrives Windows plugin only considers regular drives (i.e. C:/, D:/, E:/). Mount points inside the directory tree will no be part of the snapshots unless you set “OneFS = no” in the Options block of the FileSet, which will cause Bacula to snapshot everything.
Microsoft VSS Writer Plugin
We provide a single plugin named vss-fd.dll that permits you to backup a number of different components on Windows machines. This plugin is available from Bacula Systems as an option.Please write to the Support Team to find more information about our VSS products.
- System State writers
- Registry
- Event Logs
- COM+ REGDB (COM Registration Database)
- System (Systems files - most of what is under c:/windows and more)
- Windows Management and Instrumentation (WMI)
- NT Directory Service (NTDS) (Active Directory)
- NT File Replication Service (NTFRS) (SYSVOL etc replication - Windows 2003 domains)
- Distributed File System (DFS) Replication (SYSVOLS etc replication - Windows 2008 domains)
- Automated System Recovery (ASR) Writer
- MSSQL databases (except those owned by Sharepoint if that plugin is specified).
This component has been tested, but only works for Full backups. Please do not attempt to use it for incremental backups. The Windows writer performs block level delta for Incremental backups, which are only supported by Bacula version 4.2.0, not yet released. If you use this component, please do not use it in production without careful testing. - Exchange (all exchange databases)
We have tested this component and found it to work, but only for Full backups. Please do not attempt to use it for incremental or differential backups. We are including this component for you to test. Please do not use it in production without careful testing.
Bacula Systems has a White Paper that describes backup and restore of MS Exchange 2010 in detail.
Each of the above specified Microsoft components can be backed up by specifying a different plugin option within the Bacula FileSet. All specifications must start with vss: and be followed with a keyword which indicates the writer, such as /@SYSTEMSTATE/ (see below). To activate each component you use the following:
- System State writers
Plugin = "vss:/@SYSTEMSTATE/"
Note, exactly which subcomponents will be backed up depends on which ones you have enabled within Windows. For example, on a standard default Vista system only ASR Writer, COM+ REGDB, System State, and WMI are enabled. - MSSQL databases (except those owned by Sharepoint if that plugin is specified)
Plugin = "vss:/@MSSQL/"
The Microsoft literature says that the mssql writer is only good for snapshots and it needs to be enabled via a registry tweak or else the older MSDE writer will be invoked instead. - Exchange (all exchange databases)
Plugin = "vss:/@EXCHANGE/"
The plugin directives must be specified exactly as shown above. A Job may have one or more of the vss plugins components specified.
Also ensure that the vss-fd.dll plugin is in the plugins directory on the FD doing the backup, and that the plugin directory config line is present in the FD's configuration file (bacula-fd.conf).
Backup
If everything is set up correctly as above then the backup should include the system state. The system state files backed up will appear in a bconsole or BAT restore like:/@SYSTEMSTATE/ /@SYSTEMSTATE/ASR Writer/ /@SYSTEMSTATE/COM+ REGDB Writer/etc
Only a complete backup of the system state is supported at this time. That is it is not currently possible to just back up the Registry or Active Directory by itself. In almost all cases a complete backup is a good idea anyway as most of the components are interconnected in some way. Also, if an incremental or differential backup is specified on the backup Job then a full backup of the system state will still be done. The size varies according to your installation. We have seen up to 6GB under Windows 2008, mostly because of the “System” writer, and up to 20GB on Vista. The actual size depends on how many Windows components are enabled.
The system state component automatically respects all the excludes present in the FilesNotToBackup registry key, which includes things like %TEMP%, pagefile.sys, hiberfil.sys, etc. Each plugin may additionally specify files to exclude, eg the VSS Registry Writer will tell Bacula to not back up the registry hives under C:\WINDOWS\system32\config because they are backed up as part of the system state.
Restore
In most cases a restore of the entire backed up system state is recommended. Individual writers can be selected for restore, but currently not individual components of those writers. To restore just the Registry, you would need to mark @SYSTEMSTATE (only the directory, not the subdirectories), and then do mark Registry* to mark the Registry writer and everything under it.Restoring anything less than a single component may not produce the intended results and should only be done if a specific need arises and you know what you are doing, and not without testing on a non-critical system first.
To restore Active Directory, the system will need to be booted into Directory Services Restore Mode, an option at Windows boot time.
Only a non-authoritative restore of NTFRS/DFSR is supported at this time. There exists Windows literature to turn a Domain Controller (DC) restored in non-authoritative mode back into an authoritative Domain Controller. If only one DC exists it appears that Windows does an authoritative restore anyway.
Most VSS components will want to restore to files that are currently in use. A reboot will be required to complete the restore (eg to bring the restored registry online).
Starting another restore of VSS data after the restore of the registry without first rebooting will not produce the intended results as the “to be replaced next reboot” file list will only be updated in the “to be replaced” copy of the registry and so will not be actioned.
Example
Suppose you have the following backup FileSet:
@SYSTEMSTATE/
System Writer/
instance_{GUID}
System Files/
Registry Writer/
instance_{GUID}
Registry/
COM+ REGDB Writer/
instance_{GUID}
COM+ REGDB/
NTDS/
instance_{GUID}
ntds/
If only the Registry needs to be restored, then you could use the following commands in bconsole:
markdir @SYSTEMSTATE cd @SYSTEMSTATE markdir "Registry Writer" cd "Registry Writer" mark instance* mark "Registry"
Windows Plugins Items to Note
- Reboot Required after a Plugin Restore
In general after any VSS plugin is used to restore a component, you will need to reboot the system. This is required because in-use files cannot be replaced during restore time, so they are noted in the registry and replaced when the system reboots. - After a System State restore, a reboot will generally take longer than normal because the pre-boot process must move the newly restored files into their final place prior to actually booting the OS.
- One File from Each Drive needed by the Plugins must be backed up
At least one file from each drive that will be needed by the plugin must have a regular file that is marked for backup. This is to ensure that the main Bacula code does a snapshot of all the required drives. At a later time, we will find a way to accomplish this automatically. - Bacula does not Automatically Backup Mounted Drives
Any drive that is mounted in the normal file structure using a mount point or junction point will not be backed up by Bacula. If you want it backed up, you must explicitly mention it in a Bacula “File” directive in your FileSet. - When doing a backup that is to be used as a Bare Metal Recovery, do not use the VSS plugin. The reason is that during a Bare Metal Recovery, VSS is not available nor are the writers from the various components that are needed to do the restore. You might do full backup to be used with a Bare Metal Recovery once a month or once a week, and all other days, do a backup using the VSS plugin, but under a different Job name. Then to restore your system, use the last Full non-VSS backup to restore your system, and after rebooting do a restore with the VSS plugin to get everything fully up to date.
This plugin is available as an option. Please contact Bacula Systems to get access to the VSS Plugin packages and the documentation.
Support for NDMP Protocol
The new ndmp Plugin is able to backup a NAS through NDMP protocol using Filer to server approach, where the Filer is backing up across the LAN to your Bacula server.
Accurate option should be turned on in the Job resource.
Job {
Accurate = yes
FileSet = NDMPFS
...
}
FileSet {
Name = NDMPFS
...
Include {
Plugin = "ndmp:host=nasbox user=root pass=root file=/vol/vol1"
}
}
This plugin is available as an option. Please contact Bacula Systems to get access to the NDMP Plugin packages and the documentation.
Incremental Accelerator Plugin for NetApp
The Incremental Accelerator for NetApp Plugin is designed to simplify the backup and restore procedure of your NetApp NAS hosting a huge number of files.
When using the NetApp HFC Plugin, Bacula Enterprise will query the NetApp device to get the list of all files modified since the last backup instead of having to walk through the entire filesystem. Once Bacula have the list of all files to back's up, it will use a standard network share (such as NFS or CIFS) to access files.
This plugin is available as an option. Please contact Bacula Systems to get access to the Incremental Accelerator Plugin for NetApp packages and the documentation.
PostgreSQL Plugin
The PostgreSQL plugin is designed to simplify the backup and restore procedure of your PostgreSQL cluster, the backup administrator doesn't need to learn about internals of PostgreSQL backup techniques or write complex scripts. The plugin will automatically take care for you to backup essential information such as configuration, users definition or tablespaces. The PostgreSQL plugin supports both dump and Point In Time Recovery (PITR) backup techniques.
This plugin is available as an option. Please contact Bacula Systems to get access to the PostgreSQL Plugin packages and the documentation.
VMWare vSphere VADP Plugin
The Bacula Enterprise vSphere plugin provides virtual machine bare metal recovery, while the backup at the guest level simplify data protection of critical applications.
The plugin integrates the VMware's Changed Block Tracking (CBT) technology to ensure only blocks that have changed since the initial Full, and/or the last Incremental or Differential Backup are sent to the current Incremental or Differential backup stream to give you more efficient backups and reduced network load.
This plugin is available as an option. Please contact Bacula Systems to get access to the vSphere Plugin packages and the documentation.
Oracle RMAN Plugin
The Bacula Enterprise Oracle Plugin is designed to simplify the backup and restore procedure of your Oracle Database instance, the backup administrator don't need to learn about internals of Oracle backup techniques or write complex scripts. The Bacula Enterprise Oracle plugin supports both dump and PITR with Oracle Recovery Manager (RMAN) backup techniques.
This plugin is available as an option. Please contact Bacula Systems to get access to the Oracle Plugin packages and the documentation.
The Client Resource
The Client resource defines the attributes of the Clients that are served by this Director; that is the machines that are to be backed up. You will need one Client resource definition for each machine to be backed up.
- Client (or FileDaemon)
- Start of the Client directives.
- Name = <name>
- The client name which will be used in the Job resource directive or in the console run command. This directive is required.
- Enabled = <yes|no>
- This directive allows you to enable or disable the Client resource. If the resource is disabled, the Client will not be used.
- Address = <address>
- Where the <address> is a host name, a fully qualified domain name, or a network address in dotted quad notation for a Bacula File server daemon. This directive is required.
- FD Port = <port-number>
- Where the <port-number> is a port number at which the Bacula File server daemon can be contacted. The default is 9102.
- AllowFDConnections = <yes|no>
-
When AllowFDConnections is set to true, the Director will accept incoming connections from the Client and will keep the socket open for a future use. The Director will no longer use the Address to contact the File Daemon. This configuration is useful if the Director cannot contact the FileDaemon directly. See (here) for more information. The default value is no.
- Catalog = <Catalog-resource-name>
- This specifies the name of the catalog resource to be used for this Client. This directive is required.
- Password = <password>
- This is the password to be used when establishing a connection with the File services, so the Client configuration file on the machine to be backed up must have the same password defined for this Director. This directive is required. If you have either /dev/random or bc on your machine, Bacula will generate a random password during the configuration process, otherwise it will be left blank.
The password is plain text. It is not generated through any special process, but it is preferable for security reasons to make the text random.
- Snapshot Retention = <time-period-specification>
-
The Snapshot Retention directive defines the length of time that Bacula will keep Snapshots in the Catalog database and on the Client after the Snapshot creation. When this time period expires, and if using the snapshot prune command, Bacula will prune (remove) Snapshot records that are older than the specified Snapshot Retention period and will contact the FileDaemon to delete Snapshots from the system.
The Snapshot retention period is specified as seconds, minutes, hours, days, weeks, months, quarters, or years. See the Configuration chapter of this manual for additional details of time specification.
The default is 0 seconds, Snapshots are deleted at the end of the backup. The Job SnapshotRetention directive overwrites the Client SnapshotRetention directive.
- File Retention = <time-period-specification>
- The File Retention directive defines the length of time that Bacula will keep File records in the Catalog database after the End time of the Job corresponding to the File records. When this time period expires, and if AutoPrune is set to yes Bacula will prune (remove) File records that are older than the specified File Retention period. Note, this affects only records in the catalog database. It does not affect your archive backups.
File records may actually be retained for a shorter period than you specify on this directive if you specify either a shorter Job Retention or a shorter Volume Retention period. The shortest retention period of the three takes precedence. The time may be expressed in seconds, minutes, hours, days, weeks, months, quarters, or years. See the Configuration chapter of this manual for additional details of time specification.
The default is 60 days.
- Job Retention = <time-period-specification>
- The Job Retention directive defines the length of time that Bacula will keep Job records in the Catalog database after the Job End time. When this time period expires, and if AutoPrune is set to yes Bacula will prune (remove) Job records that are older than the specified File Retention period. As with the other retention periods, this affects only records in the catalog and not data in your archive backup.
If a Job record is selected for pruning, all associated File and JobMedia records will also be pruned regardless of the File Retention period set. As a consequence, you normally will set the File retention period to be less than the Job retention period. The Job retention period can actually be less than the value you specify here if you set the Volume Retention directive in the Pool resource to a smaller duration. This is because the Job retention period and the Volume retention period are independently applied, so the smaller of the two takes precedence.
The Job retention period is specified as seconds, minutes, hours, days, weeks, months, quarters, or years. See the Configuration chapter of this manual for additional details of time specification.
- AutoPrune = <yes|no>
- If AutoPrune is set to yes (default), Bacula (version 1.20 or greater) will automatically apply the File retention period and the Job retention period for the Client at the end of the Job. If you set AutoPrune = no, pruning will not be done, and your Catalog will grow in size each time you run a Job. Pruning affects only information in the catalog and not data stored in the backup archives (on Volumes).
- Maximum Concurrent Jobs = <number>
- where <number> is the maximum number of Jobs with the current Client that can run concurrently. Note, this directive limits only Jobs for Clients with the same name as the resource in which it appears. Any other restrictions on the maximum concurrent jobs such as in the Director, Job, or Storage resources will also apply in addition to any limit specified here. The default is set to 1, but you may set it to a larger number. If set to a large value, please be careful to not have this value higher than the Maximum Concurrent Jobs configured in the Client resource in the Client/File daemon configuration file. Otherwise, backup jobs can fail due to the Director connection to FD be refused because Maximum Concurrent Jobs was exceeded on FD side.
- Maximum Bandwidth Per Job = <speed>
-
The speed parameter specifies the maximum allowed bandwidth in bytes that a job may use when started for this Client. You may specify the following speed parameter modifiers: kb/s (1,000 bytes per second), k/s (1,024 bytes per second), mb/s (1,000,000 bytes per second), or m/s (1,048,576 bytes per second).
The use of TLS, TLS PSK, CommLine compression and Deduplication can interfer with the value set with the Directive.
- Priority = <number>
- The number specifies the priority of this client relative to other clients that the Director is processing simultaneously. The priority can range from 1 to 1000. The clients are ordered such that the smaller number priorities are performed first (not currently implemented).
- SD Calls Client = <yes|no>
-
If the SD Calls Client directive is set to true in a Client resource any Backup, Restore, Verify Job where the client is involved, the client will wait for the Storage daemon to contact it. By default this directive is set to false, and the Client will call the Storage daemon as it always has. This directive can be useful if your Storage daemon is behind a firewall that permits outgoing connections but not incoming connections.
- FD Storage Address = <address>
- Where the <address> is a host name, a , or an IP address. The <address> specified here will be transmitted to the File daemon instead of the IP address that the Director uses to contact the Storage daemon. This FDStorageAddress will then be used by the File daemon to contact the Storage daemon. This directive particularly useful if the File daemon is in a different network domain than the Director or Storage daemon. It is also useful in NAT or firewal environments.
- TLS Enable = <yes|no>
-
Enable TLS support. If TLS is not enabled, none of the other TLS directives have any effect. In other words, even if you set TLS Require = yes you need to have TLS enabled or TLS will not be used.
- TLS PSK Enable = <yes|no>
-
Enable or Disable automatic TLS PSK support. TLS PSK is enabled by default between all Bacula components. The Pre-Shared Key used between the programs is the Bacula password. If both TLS Enable and TLS PSK Enable are enabled, the system will use TLS certificates.
- TLS Require = <yes|no>
-
Require TLS or TLS-PSK encryption. This directive is ignored unless one of TLS Enable or TLS PSK Enable is set to yes. If TLS is not required while TLS or TLS-PSK are enabled, then the Bacula component will connect with other components either with or without TLS or TLS-PSK
If TLS or TLS-PSK is enabled and TLS is required, then the Bacula component will refuse any connection request that does not use TLS.
- TLS Authenticate = <yes|no>
- When TLS Authenticate is enabled, after doing the CRAM-MD5 authentication, Bacula will also do TLS authentication, then TLS encryption will be turned off, and the rest of the communication between the two Bacula components will be done without encryption. If TLS-PSK is used instead of the regular TLS, the encryption is turned off after the TLS-PSK authentication step.
If you want to encrypt communications data, use the normal TLS directives but do not turn on TLS Authenticate.
- TLS Certificate = <Filename>
- The full path and filename of a PEM encoded TLS certificate. It will be used as either a client or server certificate, depending on the connection direction. PEM stands for Privacy Enhanced Mail, but in this context refers to how the certificates are encoded. This format is used because PEM files are base64 encoded and hence ASCII text based rather than binary. They may also contain encrypted information.
This directive is required in a server context, but it may not be specified in a client context if TLS Verify Peer is set to no in the corresponding server context.
Example:
File Daemon configuration file (bacula-fd.conf), Director resource configuration has TLS Verify Peer = no:
Director { Name = bacula-dir Password = "password" Address = director.example.com # TLS configuration directives TLS Enable = yes TLS Require = yes TLS Verify Peer = no TLS CA Certificate File = /opt/bacula/ssl/certs/root_cert.pem TLS Certificate = /opt/bacula/ssl/certs/client1_cert.pem TLS Key = /opt/bacula/ssl/keys/client1_key.pem }Having TLS Verify Peer = no, means the File Daemon, server context, will not check Directorâs public certificate, client context. There is no need to specify TLS Certificate File neither TLS Key directives in the Client resource, director configuration file. We can have the below client configuration in bacula-dir.conf:
Client { Name = client1-fd Address = client1.example.com FDPort = 9102 Catalog = MyCatalog Password = "password" ... # TLS configuration directives TLS Enable = yes TLS Require = yes TLS CA Certificate File = /opt/bacula/ssl/certs/ca_client1_cert.pem } - TLS Key = <Filename>
- The full path and filename of a PEM encoded TLS private key. It must correspond to the TLS certificate.
- TLS Verify Peer = <yes|no>
- Verify peer certificate. Instructs server to request and verify the client's X.509 certificate. Any client certificate signed by a known-CA will be accepted. Additionally, the client's X509 certificate Common Name must meet the value of the Address directive. If the TLSAllowed CN onfiguration directive is used, the client's x509 certificate Common Name must also correspond to one of the CN specified in the TLS Allowed CN directive. This directive is valid only for a server and not in client context. The default is yes.
- TLS Allowed CN = <string list>
- Common name attribute of allowed peer certificates. This directive is valid for a server and in a client context. If this directive is specified, the peer certificate will be verified against this list. In the case this directive is configured on a server side, the allowed CN list will not be checked if TLS Verify Peer is set to no (TLS Verify Peer is yes by default). This can be used to ensure that only the CN-approved component may connect. This directive may be specified more than once.
In the case this directive is configured in a server side, the allowed CN list will only be checked if TLS Verify Peer = yes (default). For example, in bacula-fd.conf, Director resource definition:
Director { Name = bacula-dir Password = "password" Address = director.example.com # TLS configuration directives TLS Enable = yes TLS Require = yes # if TLS Verify Peer = no, then TLS Allowed CN will not be checked. TLS Verify Peer = yes TLS Allowed CN = director.example.com TLS CA Certificate File = /opt/bacula/ssl/certs/root_cert.pem TLS Certificate = /opt/bacula/ssl/certs/client1_cert.pem TLS Key = /opt/bacula/ssl/keys/client1_key.pem }In the case this directive is configured in a client side, the allowed CN list will always be checked.
Client { Name = client1-fd Address = client1.example.com FDPort = 9102 Catalog = MyCatalog Password = "password" ... # TLS configuration directives TLS Enable = yes TLS Require = yes # the Allowed CN will be checked for this client by director # the client's certificate Common Name must match any of # the values of the Allowed CN list TLS Allowed CN = client1.example.com TLS CA Certificate File = /opt/bacula/ssl/certs/ca_client1_cert.pem TLS Certificate = /opt/bacula/ssl/certs/director_cert.pem TLS Key = /opt/bacula/ssl/keys/director_key.pem }If the client doesnât provide a certificate with a Common Name that meets any value in the TLS Allowed CN list, an error message will be issued:
16-Nov 17:30 bacula-dir JobId 0: Fatal error: bnet.c:273 TLS certificate verification failed. Peer certificate did not match a required commonName 16-Nov 17:30 bacula-dir JobId 0: Fatal error: TLS negotiation failed with FD at "192.168.100.2:9102".
- TLS CA Certificate File = <Filename>
- The full path and filename specifying a PEM encoded TLS CA certificate(s). Multiple certificates are permitted in the file. One of TLS CA Certificate File or TLS CA Certificate Dir are required in a server context, unless TLS Verify Peer (see above) is set to no, and are always required in a client context.
- TLS CA Certificate Dir = <Directory>
- Full path to TLS CA certificate directory. In the current implementation, certificates must be stored PEM encoded with OpenSSL-compatible hashes, which is the subject name's hash and an extension of .0. One of TLS CA Certificate File or TLS CA Certificate Dir are required in a server context, unless TLS Verify Peer is set to no, and are always required in a client context.
- TLS DH File = <Directory>
- Path to PEM encoded Diffie-Hellman parameter file. If this directive is specified, DH key exchange will be used for the ephemeral keying, allowing for forward secrecy of communications. DH key exchange adds an additional level of security because the key used for encryption/decryption by the server and the client is computed on each end and thus is never passed over the network if Diffie-Hellman key exchange is used. Even if DH key exchange is not used, the encryption/decryption key is always passed encrypted. This directive is only valid within a server context.
To generate the parameter file, you may use openssl:
openssl dhparam -out dh4096.pem -5 4096
The following is an example of a valid Client resource definition:
Client {
Name = Minimatou
Address = minimatou
Catalog = MySQL
Password = very_good
}
The Storage Resources
The Storage resource defines which Storage daemons are available for use by the Director.
- Storage
- Start of the Storage resources. At least one storage resource must be specified.
- Name = <name>
- The name of the storage resource. This name appears on the Storage directive specified in the Job resource and is required.
- Enabled = <yes|no>
- This directive allows you to enable or disable a Storage resource. When the resource is disabled, the storage device will not be used. To reuse it you must re-enable the Storage resource.
- Address = <address>
- Where the address is a host name, a , or an IP address. Please note that the <address> as specified here will be transmitted to the File daemon who will then use it to contact the Storage daemon. Hence, it is not, a good idea to use localhost as the name but rather a fully qualified machine name or an IP address. This directive is required.
- FD Storage Address = <address>
- Where the <address> is a host name, a , or an IP address. The <address> specified here will be transmitted to the File daemon instead of the IP address that the Director uses to contact the Storage daemon. This FDStorageAddress will then be used by the File daemon to contact the Storage daemon. This directive particularly useful if the File daemon is in a different network domain than the Director or Storage daemon. It is also useful in NAT or firewal environments.
- SD Port = <port>
- Where port is the port to use to contact the storage daemon for information and to start jobs. This same port number must appear in the Storage resource of the Storage daemon's configuration file. The default is 9103.
- Password = <password>
- This is the password to be used when establishing a connection with the Storage services. This same password also must appear in the Director resource of the Storage daemon's configuration file. This directive is required. If you have either /dev/random or bc on your machine, Bacula will generate a random password during the configuration process, otherwise it will be left blank.
The password is plain text. It is not generated through any special process, but it is preferable for security reasons to use random text.
- Device = <device-name>
- This directive specifies the Storage daemon's name of the device resource to be used for the storage. If you are using an Autochanger, the name specified here should be the name of the Storage daemon's Autochanger resource rather than the name of an individual device. This name is not the physical device name, but the logical device name as defined on the Name directive contained in the Device or the Autochanger resource definition of the Storage daemon configuration file. You can specify any name you would like (even the device name if you prefer) up to a maximum of 127 characters in length. The physical device name associated with this device is specified in the Storage daemon configuration file (as Archive Device). Please take care not to define two different Storage resource directives in the Director that point to the same Device in the Storage daemon. Doing so may cause the Storage daemon to block (or hang) attempting to open the same device that is already open. This directive is required.
- Media Type = <MediaType>
- This directive specifies the Media Type to be used to store the data. This is an arbitrary string of characters up to 127 maximum that you define. It can be anything you want. However, it is best to make it descriptive of the storage media (e.g. “File”, “DAT”, “HP DLT8000”, “8mm”, ...). In addition, it is essential that you make the Media Type specification unique for each storage media type. If you have two DDS-4 drives that have incompatible formats, or if you have a DDS-4 drive and a DDS-4 autochanger, you almost certainly should specify different Media Types. During a restore, assuming a DDS-4 Media Type is associated with the Job, Bacula can decide to use any Storage daemon that supports Media Type DDS-4 and on any drive that supports it.
If you are writing to disk Volumes, you must make doubly sure that each Device resource defined in the Storage daemon (and hence in the Director's conf file) has a unique media type. Otherwise for Bacula versions 1.38 and older, your restores may not work because Bacula will assume that you can mount any Media Type with the same name on any Device associated with that Media Type. This is possible with tape drives, but with disk drives, unless you are very clever you cannot mount a Volume in any directory - this can be done by creating an appropriate soft link.
Currently Bacula permits only a single Media Type per Storage and Device definition. Consequently, if you have a drive that supports more than one Media Type, you can give a unique string to Volumes with different intrinsic Media Type (Media Type = DDS-3-4 for DDS-3 and DDS-4 types), but then those volumes will only be mounted on drives indicated with the dual type (DDS-3-4).
If you want to tie Bacula to using a single Storage daemon or drive, you must specify a unique Media Type for that drive. This is an important point that should be carefully understood. Note, this applies equally to Disk Volumes. If you define more than one disk Device resource in your Storage daemon's conf file, the Volumes on those two devices are in fact incompatible because one can not be mounted on the other device since they are found in different directories. For this reason, you probably should use two different Media Types for your two disk Devices (even though you might think of them as both being File types). You can find more on this subject in the Basic Volume Management chapter of this manual.
The MediaType specified in the Director's Storage resource, must correspond to the Media Type specified in the Device resource of the Storage daemon configuration file. This directive is required, and it is used by the Director and the Storage daemon to ensure that a Volume automatically selected from the Pool corresponds to the physical device. If a Storage daemon handles multiple devices (e.g. will write to various file Volumes on different partitions), this directive allows you to specify exactly which device.
As mentioned above, the value specified in the Director's Storage resource must agree with the value specified in the Device resource in the Storage daemon's configuration file. It is also an additional check so that you don't try to write data for a DLT onto an 8mm device.
- Autochanger = <yes|no>
- If you specify yes for this command (the default is no), when you use the label command or the add command to create a new Volume, Bacula will also request the Autochanger Slot number. This simplifies creating database entries for Volumes in an autochanger. If you forget to specify the Slot, the autochanger will not be used. However, you may modify the Slot associated with a Volume at any time by using the update volume or update slots command in the console program. When Autochanger is enabled, the algorithm used by Bacula to search for available volumes will be modified to consider only Volumes that are known to be in the autochanger's magazine. If no in changer volume is found, Bacula will attempt recycling, pruning, ..., and if still no volume is found, Bacula will search for any volume whether or not in the magazine. By privileging in changer volumes, this procedure minimizes operator intervention. The default is no.
For the autochanger to be used, you must also specify Autochanger = yes in the Device Resource in the Storage daemon's configuration file as well as other important Storage daemon configuration information. Please consult the Using Autochangers manual of this chapter for the details of using autochangers. You can modify any additional Storage resources that correspond to devices that are part of the Autochanger device. Instead of the previous Autochanger = yes directive, the configuration should be modified to be Autochanger = xxx where xxx is the name of the Autochanger.
- Maximum Concurrent Jobs = <number>
- where <number> is the maximum number of Jobs with the current Storage resource that can run concurrently. Note, this directive limits only Jobs for Jobs using this Storage daemon. Any other restrictions on the maximum concurrent jobs such as in the Director, Job, or Client resources will also apply in addition to any limit specified here. The default is set to 1, but you may set it to a larger number. However, if you set the Storage daemon's number of concurrent jobs greater than one, we recommend that you read the waring documented under Maximum Concurrent Jobs in the Director's resource or simply turn data spooling on as documented in the Data Spooling chapter of this manual.
- Maximum Concurrent Read Jobs = <number>
-
The main purpose is to limit the number of concurrent Copy, Migration, and VirtualFull jobs so that they don't monopolize all the Storage drives causing a deadlock situation where all the drives are allocated for reading but none remain for writing. This deadlock situation can occur when running multiple simultaneous Copy, Migration, and VirtualFull jobs.
The default value is set to 0 (zero), which means there is no limit on the number of read jobs. Note, limiting the read jobs does not apply to Restore jobs, which are normally started by hand. A reasonable value for this directive is one half the number of drives that the Storage resource has rounded down. Doing so, will leave the same number of drives for writing and will generally avoid over committing drives and a deadlock.
- AllowCompression = <yes|no>
-
This directive is optional, and if you specify no (the default is yes), it will cause backups jobs running on this storage resource to run without client File Daemon compression. This effectively overrides compression options in FileSets used by jobs which use this storage resource.
- Heartbeat Interval = <time-interval>
- This directive is optional and if specified will cause the Director to set a keepalive interval (heartbeat) in seconds on each of the sockets it opens for the Storage resource. This value will override any specified at the Director level. It is implemented only on systems (Linux, ...) that provide the setsockopt TCP_KEEPIDLE function. The default value is 300s.
- TLS Enable = <yes|no>
-
Enable TLS support. If TLS is not enabled, none of the other TLS directives have any effect. In other words, even if you set TLS Require = yes you need to have TLS enabled or TLS will not be used.
- TLS PSK Enable = <yes|no>
-
Enable or Disable automatic TLS PSK support. TLS PSK is enabled by default between all Bacula components. The Pre-Shared Key used between the programs is the Bacula password. If both TLS Enable and TLS PSK Enable are enabled, the system will use TLS certificates.
- TLS Require = <yes|no>
-
Require TLS or TLS-PSK encryption. This directive is ignored unless one of TLS Enable or TLS PSK Enable is set to yes. If TLS is not required while TLS or TLS-PSK are enabled, then the Bacula component will connect with other components either with or without TLS or TLS-PSK
If TLS or TLS-PSK is enabled and TLS is required, then the Bacula component will refuse any connection request that does not use TLS.
- TLS Authenticate = <yes|no>
- When TLS Authenticate is enabled, after doing the CRAM-MD5 authentication, Bacula will also do TLS authentication, then TLS encryption will be turned off, and the rest of the communication between the two Bacula components will be done without encryption. If TLS-PSK is used instead of the regular TLS, the encryption is turned off after the TLS-PSK authentication step.
If you want to encrypt communications data, use the normal TLS directives but do not turn on TLS Authenticate.
- TLS Certificate = <Filename>
- The full path and filename of a PEM encoded TLS certificate. It will be used as either a client or server certificate, depending on the connection direction. PEM stands for Privacy Enhanced Mail, but in this context refers to how the certificates are encoded. This format is used because PEM files are base64 encoded and hence ASCII text based rather than binary. They may also contain encrypted information.
This directive is required in a server context, but it may not be specified in a client context if TLS Verify Peer is set to no in the corresponding server context.
Example:
File Daemon configuration file (bacula-fd.conf), Director resource configuration has TLS Verify Peer = no:
Director { Name = bacula-dir Password = "password" Address = director.example.com # TLS configuration directives TLS Enable = yes TLS Require = yes TLS Verify Peer = no TLS CA Certificate File = /opt/bacula/ssl/certs/root_cert.pem TLS Certificate = /opt/bacula/ssl/certs/client1_cert.pem TLS Key = /opt/bacula/ssl/keys/client1_key.pem }Having TLS Verify Peer = no, means the File Daemon, server context, will not check Directorâs public certificate, client context. There is no need to specify TLS Certificate File neither TLS Key directives in the Client resource, director configuration file. We can have the below client configuration in bacula-dir.conf:
Client { Name = client1-fd Address = client1.example.com FDPort = 9102 Catalog = MyCatalog Password = "password" ... # TLS configuration directives TLS Enable = yes TLS Require = yes TLS CA Certificate File = /opt/bacula/ssl/certs/ca_client1_cert.pem } - TLS Key = <Filename>
- The full path and filename of a PEM encoded TLS private key. It must correspond to the TLS certificate.
- TLS Verify Peer = <yes|no>
- Verify peer certificate. Instructs server to request and verify the client's X.509 certificate. Any client certificate signed by a known-CA will be accepted. Additionally, the client's X509 certificate Common Name must meet the value of the Address directive. If the TLSAllowed CN onfiguration directive is used, the client's x509 certificate Common Name must also correspond to one of the CN specified in the TLS Allowed CN directive. This directive is valid only for a server and not in client context. The default is yes.
- TLS Allowed CN = <string list>
- Common name attribute of allowed peer certificates. This directive is valid for a server and in a client context. If this directive is specified, the peer certificate will be verified against this list. In the case this directive is configured on a server side, the allowed CN list will not be checked if TLS Verify Peer is set to no (TLS Verify Peer is yes by default). This can be used to ensure that only the CN-approved component may connect. This directive may be specified more than once.
In the case this directive is configured in a server side, the allowed CN list will only be checked if TLS Verify Peer = yes (default). For example, in bacula-fd.conf, Director resource definition:
Director { Name = bacula-dir Password = "password" Address = director.example.com # TLS configuration directives TLS Enable = yes TLS Require = yes # if TLS Verify Peer = no, then TLS Allowed CN will not be checked. TLS Verify Peer = yes TLS Allowed CN = director.example.com TLS CA Certificate File = /opt/bacula/ssl/certs/root_cert.pem TLS Certificate = /opt/bacula/ssl/certs/client1_cert.pem TLS Key = /opt/bacula/ssl/keys/client1_key.pem }In the case this directive is configured in a client side, the allowed CN list will always be checked.
Client { Name = client1-fd Address = client1.example.com FDPort = 9102 Catalog = MyCatalog Password = "password" ... # TLS configuration directives TLS Enable = yes TLS Require = yes # the Allowed CN will be checked for this client by director # the client's certificate Common Name must match any of # the values of the Allowed CN list TLS Allowed CN = client1.example.com TLS CA Certificate File = /opt/bacula/ssl/certs/ca_client1_cert.pem TLS Certificate = /opt/bacula/ssl/certs/director_cert.pem TLS Key = /opt/bacula/ssl/keys/director_key.pem }If the client doesnât provide a certificate with a Common Name that meets any value in the TLS Allowed CN list, an error message will be issued:
16-Nov 17:30 bacula-dir JobId 0: Fatal error: bnet.c:273 TLS certificate verification failed. Peer certificate did not match a required commonName 16-Nov 17:30 bacula-dir JobId 0: Fatal error: TLS negotiation failed with FD at "192.168.100.2:9102".
- TLS CA Certificate File = <Filename>
- The full path and filename specifying a PEM encoded TLS CA certificate(s). Multiple certificates are permitted in the file. One of TLS CA Certificate File or TLS CA Certificate Dir are required in a server context, unless TLS Verify Peer (see above) is set to no, and are always required in a client context.
- TLS CA Certificate Dir = <Directory>
- Full path to TLS CA certificate directory. In the current implementation, certificates must be stored PEM encoded with OpenSSL-compatible hashes, which is the subject name's hash and an extension of .0. One of TLS CA Certificate File or TLS CA Certificate Dir are required in a server context, unless TLS Verify Peer is set to no, and are always required in a client context.
- TLS DH File = <Directory>
- Path to PEM encoded Diffie-Hellman parameter file. If this directive is specified, DH key exchange will be used for the ephemeral keying, allowing for forward secrecy of communications. DH key exchange adds an additional level of security because the key used for encryption/decryption by the server and the client is computed on each end and thus is never passed over the network if Diffie-Hellman key exchange is used. Even if DH key exchange is not used, the encryption/decryption key is always passed encrypted. This directive is only valid within a server context.
To generate the parameter file, you may use openssl:
openssl dhparam -out dh4096.pem -5 4096

The following is an example of a valid Storage resource definition:
# Definition of tape storage device
Storage {
Name = DLTDrive
Address = lpmatou
Password = storage_password # password for Storage daemon
Device = "HP DLT 80" # same as Device in Storage daemon
Media Type = DLT8000 # same as MediaType in Storage daemon
}
The Autochanger Resources
Each autochanger that you have defined in an Autochanger resource in the Storage daemon's bacula-sd.conf file, must have a corresponding Autochanger resource defined in the Director's bacula-dir.conf file. The Autochanger resource uses the same directives as the Storage resource defined (here).
Normally you will already have a Storage resource that points to the Storage daemon's Autochanger resource. Thus you need only to change the name of the Storage resource to Autochanger. In addition the Autochanger = yes directive is not needed in the Director's Autochanger resource, since the resource name is Autochanger, the Director already knows that it represents an autochanger.
In addition to the above change (Storage to Autochanger), you must modify any additional Storage resources that correspond to devices that are part of the Autochanger device. Instead of the previous Autochanger = yes directive, the configuration should be modified to be Autochanger = xxx where xxx is the name of the Autochanger.
For example, in the bacula-dir.conf file:
Autochanger { # New resource
Name = Changer-1
Address = cibou.company.com
SDPort = 9103
Password = "xxxxxxxxxx"
Device = LTO-Changer-1
Media Type = LTO-4
Maximum Concurrent Jobs = 50
}
Storage {
Name = Changer-1-Drive0
Address = cibou.company.com
SDPort = 9103
Password = "xxxxxxxxxx"
Device = LTO4_1_Drive0
Media Type = LTO-4
Maximum Concurrent Jobs = 5
Autochanger = Changer-1 # New directive
}
Storage {
Name = Changer-1-Drive1
Address = cibou.company.com
SDPort = 9103
Password = "xxxxxxxxxx"
Device = LTO4_1_Drive1
Media Type = LTO-4
Maximum Concurrent Jobs = 5
Autochanger = Changer-1 # New directive
}
...
Note that Storage resources Changer-1-Drive0 and Changer-1-Drive1 are not required since they make up part of an autochanger, and normally, Jobs refer only to the Autochanger resource. However, by referring to those Storage definitions in a Job, you will use only the indicated drive. This is not normally what you want to do, but it is very useful and often used for reserving a drive for restores. See the Storage daemon example configuration below and the use of AutoSelect = no.
The Pool Resource
The Pool resource defines the set of storage Volumes (tapes or files) to be used by Bacula to write the data. By configuring different Pools, you can determine which set of Volumes (media) receives the backup data. This permits, for example, to store all full backup data on one set of Volumes and all incremental backups on another set of Volumes. Alternatively, you could assign a different set of Volumes to each machine that you backup. This is most easily done by defining multiple Pools.
Another important aspect of a Pool is that it contains the default attributes (Maximum Jobs, Retention Period, Recycle flag, ...) that will be given to a Volume when it is created. This avoids the need for you to answer a large number of questions when labeling a new Volume. Each of these attributes can later be changed on a Volume by Volume basis using the update command in the console program. Note that you must explicitly specify which Pool Bacula is to use with each Job. Bacula will not automatically search for the correct Pool.
Most often in Bacula installations all backups for all machines (Clients) go to a single set of Volumes. In this case, you will probably only use the Default Pool. If your backup strategy calls for you to mount a different tape each day, you will probably want to define a separate Pool for each day. For more information on this subject, please see the Backup Strategies chapter of this manual.
To use a Pool, there are three distinct steps. First the Pool must be defined in the Director's configuration file. Then the Pool must be written to the Catalog database. This is done automatically by the Director each time that it starts, or alternatively can be done using the create command in the console program. Finally, if you change the Pool definition in the Director's configuration file and restart Bacula, the pool will be updated alternatively you can use the update pool console command to refresh the database image. It is this database image rather than the Director's resource image that is used for the default Volume attributes. Note, for the pool to be automatically created or updated, it must be explicitly referenced by a Job resource.
Next the physical media must be labeled. The labeling can either be done with the label command in the console program or using the btape program. The preferred method is to use the label command in the console program.
Finally, you must add Volume names (and their attributes) to the Pool. For Volumes to be used by Bacula they must be of the same Media Type as the archive device specified for the job (i.e. if you are going to back up to a DLT device, the Pool must have DLT volumes defined since 8mm volumes cannot be mounted on a DLT drive). The Media Type has particular importance if you are backing up to files. When running a Job, you must explicitly specify which Pool to use. Bacula will then automatically select the next Volume to use from the Pool, but it will ensure that the Media Type of any Volume selected from the Pool is identical to that required by the Storage resource you have specified for the Job.
If you use the label command in the console program to label the Volumes, they will automatically be added to the Pool, so this last step is not normally required.
It is also possible to add Volumes to the database without explicitly labeling the physical volume. This is done with the add console command.
As previously mentioned, each time Bacula starts, it scans all the Pools associated with each Catalog, and if the database record does not already exist, it will be created from the Pool Resource definition. Bacula probably should do an update pool if you change the Pool definition, but currently, you must do this manually using the update pool command in the Console program.
The Pool Resource defined in the Director's configuration file (bacula-dir.conf) may contain the following directives:
- Pool
- Start of the Pool resource. There must be at least one Pool resource defined.
- Name = <name>
- The name of the pool. For most applications, you will use the default pool name Default. This directive is required.
- Maximum Volumes = <number>
- This directive specifies the maximum number of volumes (tapes or files) contained in the pool. This directive is optional, if omitted or set to zero, any number of volumes will be permitted. In general, this directive is useful for Autochangers where there is a fixed number of Volumes, or for File storage where you wish to ensure that the backups made to disk files do not become too numerous or consume too much space.
This directive is only respected in case of volumes automatically created by Bacula. If you add volumes to a pool manually with the label command, it is possible to have more volumes in a pool than specified by Maximum Volumes.
- Maximum Pool Bytes = <size>
-
This directive specifies the total maximum size of volumes (tapes or files) contained in the pool. This directive is optional, if omitted or set to zero, any size will be permitted. The current size of the pool can be displayed with llist pool command. All type of volumes with any status are counted in the pool size. To exclude Pruned and Recycled volumes from the quota, the RecyclePool directive can be used to send back pruned volumes to the Scratch pool for example.
- Pool Type = <type>
- This directive defines the pool type, which corresponds to the type of Job being run. It is required and may be one of the following:
- [Backup]
- [*Archive]
- [*Cloned]
- [*Migration]
- [*Copy]
- [*Save]
- Storage = <storage-resource-name>
- The Storage directive defines the name of the storage services where you want to backup the FileSet data. For additional details, see the Storage Resource Chapter of this manual. The Storage resource may also be specified in the Job resource, but the value, if any, in the Pool resource overrides any value in the Job. This Storage resource definition is not required by either the Job resource or in the Pool, but it must be specified in one or the other. If not configuration error will result.
- Use Volume Once = <yes|no>
- This directive if set to yes specifies that each volume is to be used only once. This is most useful when the Media is a file and you want a new file for each backup that is done. The default is no (i.e. use volume any number of times). This directive will most likely be phased out (deprecated), so you are recommended to use Maximum Volume Jobs = 1 instead.
The value defined by this directive in the bacula-dir.conf file is the default value used when a Volume is created. Once the volume is created, changing the value in the bacula-dir.conf file will not change what is stored for the Volume. To change the value for an existing Volume you must use the update command in the Console.
Please see the notes below under Maximum Volume Jobs concerning using this directive with multiple simultaneous jobs.
- Maximum Volume Jobs = <positive-integer>
- This directive specifies the maximum number of Jobs that can be written to the Volume. If you specify zero (0) (the default), there is no limit. Otherwise, when the number of Jobs backed up to the Volume equals <positive-integer> the Volume will be marked Used. When the Volume is marked Used it can no longer be used for appending Jobs, much like the Full status. A Volume that is marked Used or Full can be recycled if recycling is enabled, and thus used again. By setting MaximumVolumeJobs to 1, you get the same effect as setting UseVolumeOnce = yes.
The value defined by this directive in the bacula-dir.conf file is the default value used when a Volume is created. Once the volume is created, changing the value in the bacula-dir.conf file will not change what is stored for the Volume. To change the value for an existing Volume you must use the update command in the Console.
If you are running multiple simultaneous jobs, this directive may not work correctly because when a drive is reserved for a job, this directive is not taken into account, so multiple jobs may try to start writing to the Volume. At some point, when the Media record is updated, multiple simultaneous jobs may fail since the Volume can no longer be written.
- Maximum Volume Files = <positive-integer>
- This directive specifies the maximum number of files that can be written to the Volume. If you specify zero (0, the default), there is no limit. Otherwise, when the number of files written to the Volume equals <positive-integer> the Volume will be marked Used. When the Volume is marked Used it can no longer be used for appending Jobs, much like the Full status, but it can be recycled if recycling is enabled and thus used again. This value is checked and the Used status is set only at the end of a job that writes to the particular volume.
The value defined by this directive in the bacula-dir.conf file is the default value used when a Volume is created. Once the volume is created, changing the value in the bacula-dir.conf file will not change what is stored for the Volume. To change the value for an existing Volume you must use the update command in the Console.
- Maximum Volume Bytes = <size>
- This directive specifies the maximum number of bytes that can be written to the Volume. If you specify zero (0,the default), there is no limit except the physical size of the Volume. Otherwise, when the number of bytes written to the Volume equals <size> the Volume will be marked Full. When the Volume is marked Full it can no longer be used for appending Jobs, but it can be recycled if recycling is enabled, and thus the Volume can be re-used after recycling. The size specified is checked just before each block is written to the Volume and if the Volume size would exceed the specified Maximum Volume Bytes the Full status will be set and the Job will request the next available Volume to continue.
This directive is particularly useful for restricting the size of disk volumes, and will work correctly even in the case of multiple simultaneous jobs writing to the volume.
The value defined by this directive in the bacula-dir.conf file is the default value used when a Volume is created. Once the volume is created, changing the value in the bacula-dir.conf file will not change what is stored for the Volume. To change the value for an existing Volume you must use the update command in the Console.
- Volume Use Duration = <time-period-specification>
- The Volume Use Duration directive defines the time period that the Volume can be written beginning from the time of first data write to the Volume. If the time-period specified is zero (0,the default), the Volume can be written indefinitely. Otherwise, the next time a job runs that wants to access this Volume, and the time period from the first write to the volume (the first Job written) exceeds the time-period-specification, the Volume will be marked Used, which means that no more Jobs can be appended to the Volume, but it may be recycled if recycling is enabled. Using the command status dir applies algorithms similar to running jobs, so during such a command, the Volume status may also be changed. Once the Volume is recycled, it will be available for use again.
You might use this directive, for example, if you have a Volume used for Incremental backups, and Volumes used for Weekly Full backups. Once the Full backup is done, you will want to use a different Incremental Volume. This can be accomplished by setting the Volume Use Duration for the Incremental Volume to six days. I.e. it will be used for the 6 days following a Full save, then a different Incremental volume will be used. Be careful about setting the duration to short periods such as 23 hours, or you might experience problems of Bacula waiting for a tape over the weekend only to complete the backups Monday morning when an operator mounts a new tape.
The use duration is checked and the Used status is set only at the end of a job that writes to the particular volume, which means that even though the use duration may have expired, the catalog entry will not be updated until the next job that uses this volume is run. This directive is not intended to be used to limit volume sizes and may not work as expected (i.e. will fail jobs) if the use duration expires while multiple simultaneous jobs are writing to the volume.
Please note that the value defined by this directive in the bacula-dir.conf file is the default value used when a Volume is created. Once the volume is created, changing the value in the bacula-dir.conf file will not change what is stored for the Volume. To change the value for an existing Volume you must use the update volume command in the Bacula Enterprise Console manual.
- Catalog Files = <yes|no>
- This directive defines whether or not you want the names of the files that were saved to be put into the catalog. The default is yes. The advantage of specifying Catalog Files = No is that you will have a significantly smaller Catalog database. The disadvantage is that you will not be able to produce a Catalog listing of the files backed up for each Job (this is often called Browsing). Also, without the File entries in the catalog, you will not be able to use the Console restore command nor any other command that references File entries.
- AutoPrune = <yes|no>
- If AutoPrune is set to yes (default), Bacula (version 1.20 or greater) will automatically apply the Volume Retention period when new Volume is needed and no appendable Volumes exist in the Pool. Volume pruning causes expired Jobs (older than the Volume Retention period) to be deleted from the Catalog and permits possible recycling of the Volume.
- Volume Retention = <time-period-specification>
- The Volume Retention directive defines the longest amount of time that Bacula will keep records associated with the Volume in the Catalog database after the end time of each Job written to the Volume. When this time period expires, and if AutoPrune is set to yes Bacula may prune (remove) Job records that are older than the specified Volume Retention period if it is necessary to free up a Volume. Note, it is also possible for all the Job and File records to be pruned before the Volume Retention period if Job and File Retention periods are configured to a lower value. In that case the Volume can then be marked Pruned and subsequently recycled prior to expiration of the Volume Retention period.
Recycling will not occur until it is absolutely necessary to free up a volume (i.e. no other writable volume exists). All File records associated with pruned Jobs are also pruned. The time may be specified as seconds, minutes, hours, days, weeks, months, quarters, or years. The Volume Retention is applied independently of the Job Retention and the File Retention periods defined in the Client resource. This means that all the retention periods are applied in turn and that the shorter period is the one that effectively takes precedence. Note, that when the Volume Retention period has been reached, and it is necessary to obtain a new volume, Bacula will prune both the Job and the File records. And the inverse is also true that if all the Job and File records that refer to a Volume were already pruned, then the Volume may be recycled regardless of its retention period. Pruning may also occur during a status dir command because it uses similar algorithms for finding the next available Volume.
It is important to know that when the Volume Retention period expires, or all the Job and File records have been pruned that refer to a Volume, Bacula does not automatically recycle a Volume. It attempts to keep the Volume data intact as long as possible before over writing the Volume.
By defining multiple Pools with different Volume Retention periods, you may effectively have a set of tapes that is recycled weekly, another Pool of tapes that is recycled monthly and so on. However, one must keep in mind that if your Volume Retention period is too short, it may prune the last valid Full backup, and hence until the next Full backup is done, you will not have a complete backup of your system, and in addition, the next Incremental or Differential backup will be promoted to a Full backup. As a consequence, the minimum Volume Retention period should be at twice the interval of your Full backups. This means that if you do a Full backup once a month, the minimum Volume retention period should be two months.
The default Volume retention period is 365 days, and either the default or the value defined by this directive in the bacula-dir.conf file is the default value used when a Volume is created. Once the volume is created, changing the value in the bacula-dir.conf file will not change what is stored for the Volume. To change the value for an existing Volume you must use the update command in the Console.
To disable the Volume Retention feature, it is possible to set the directive to 0. When disabled, the pruning will be done only on the Job Retention directives and the "ExpiresIn" information available in the list volume output is not available.
- Cache Retention = <time-period-specification>
- The Cache Retention directive defines the longest amount of time that bacula will keep Parts associated with the Volume in the Storage daemon Cache directory after a successful upload to the Cloud. When this time period expires, and if the cloud prune command is issued, Bacula may prune (remove) Parts that are older than the specified Cache Retention period.
Note, it is also possible for all the Parts to be removed before the Cache Retention period is reached. In that case the cloud truncate command must be used.
- Action On Purge = <Truncate
The directive ActionOnPurge = Truncate instructs Bacula to permit the Volume to be truncated after it has been purged. Note: the ActionOnPurge is a bit misleading since the volume is not actually truncated when it is purged, but is enabled to be truncated. The actual truncation is done with the truncate command.
To actually truncate a Volume, you must first set the ActionOnPurge to Truncate in the Pool, then you must ensure that any existing Volumes also have this information in them, by doing an update Volumes comand. Finally, after the Volume has been purged, you may then truncate it. It is useful to prevent disk based volumes from consuming too much space. See below for more details of how to ensure Volumes are truncated after being purged.
First set the Pool to permit truncation.
Pool { Name = Default Action On Purge = Truncate ... }Then assuming a Volume has been Purged, you can schedule truncate operation at the end of your CatalogBackup job like in this example:
Job { Name = CatalogBackup ... RunScript { RunsWhen=After RunsOnClient=No Console = "truncate Volume allpools storage=File" } }- ScratchPool = <pool-resource-name>
- This directive permits specifing a specific scratch Pool to be used for the Job. This pool will replace the default scratch pool named Scratch for volume selection. For more information about scratch pools see Scratch Pool section of this manual. This directive is useful when using multiple storage devices that share the same MediaType or when you want to dedicate volumes to a particular set of pools.
- RecyclePool = <pool-resource-name>
- This directive defines to which pool the Volume will be placed (moved) when it is recycled. Without this directive, a Volume will remain in the same pool when it is recycled. With this directive, it will be moved automatically to any existing pool during a recycle. This directive is probably most useful when defined in the Scratch pool, so that volumes will be recycled back into the Scratch pool. For more on the see the Scratch Pool section of this manual.
Although this directive is called RecyclePool, the Volume in question is actually moved from its current pool to the one you specify on this directive when Bacula prunes the Volume and discovers that there are no records left in the catalog and hence marks it as Purged.
- Recycle = <yes|no>
- This directive specifies whether or not Purged Volumes may be recycled. If it is set to yes (default) and Bacula needs a volume but finds none that are appendable, it will search for and recycle (reuse) Purged Volumes (i.e. volumes with all the Jobs and Files expired and thus deleted from the Catalog). If the Volume is recycled, all previous data written to that Volume will be overwritten. If Recycle is set to no, the Volume will not be recycled, and hence, the data will remain valid. If you want to reuse (re-write) the Volume, and the recycle flag is no (0 in the catalog), you may manually set the recycle flag (update command) for a Volume to be reused.
Please note that the value defined by this directive in the bacula-dir.conf file is the default value used when a Volume is created. Once the volume is created, changing the value in the bacula-dir.conf file will not change what is stored for the Volume. To change the value for an existing Volume you must use the update command in the Console.
When all Job and File records have been pruned or purged from the catalog for a particular Volume, if that Volume is marked as Full or Used, it will then be marked as Purged. Only Volumes marked as Purged will be considered to be converted to the Recycled state if the Recycle directive is set to yes.
- Recycle Oldest Volume = <yes|no>
- This directive instructs the Director to search for the oldest used Volume in the Pool when another Volume is requested by the Storage daemon and none are available. The catalog is then pruned respecting the retention periods of all Files and Jobs written to this Volume. If all Jobs are pruned (i.e. the volume is Purged), then the Volume is recycled and will be used as the next Volume to be written. This directive respects any Job, File, or Volume retention periods that you may have specified, and as such it is much better to use this directive than the Purge Oldest Volume.
This directive can be useful if you have a fixed number of Volumes in the Pool and you want to cycle through them and you have specified the correct retention periods.
However, if you use this directive and have only one Volume in the Pool, you will immediately recycle your Volume if you fill it and Bacula needs another one. Thus your backup will be totally invalid. Please use this directive with care. The default is no.
- Recycle Current Volume = <yes|no>
- If Bacula needs a new Volume, this directive instructs Bacula to Prune the volume respecting the Job and File retention periods. If all Jobs are pruned (i.e. the volume is Purged), then the Volume is recycled and will be used as the next Volume to be written. This directive respects any Job, File, or Volume retention periods that you may have specified, and thus it is much better to use it rather than the Purge Oldest Volume directive.
This directive can be useful if you have a fixed number of Volumes in the Pool, you want to cycle through them, and you have specified retention periods that prune Volumes before you have cycled through the Volume in the Pool.
However, if you use this directive and have only one Volume in the Pool, you will immediately recycle your Volume if you fill it and Bacula needs another one. Thus your backup will be totally invalid. Please use this directive with care. The default is no.
- Purge Oldest Volume = <yes|no>
- This directive instructs the Director to search for the oldest used Volume in the Pool when another Volume is requested by the Storage daemon and none are available. The catalog is then purged irrespective of retention periods of all Files and Jobs written to this Volume. The Volume is then recycled and will be used as the next Volume to be written. This directive overrides any Job, File, or Volume retention periods that you may have specified.
This directive can be useful if you have a fixed number of Volumes in the Pool and you want to cycle through them and reusing the oldest one when all Volumes are full, but you don't want to worry about setting proper retention periods. However, by using this option you risk losing valuable data.
Please be aware that Purge Oldest Volume disregards all retention periods. If you have only a single Volume defined and you turn this variable on, that Volume will always be immediately overwritten when it fills! So at a minimum, ensure that you have a decent number of Volumes in your Pool before running any jobs. If you want retention periods to apply do not use this directive. To specify a retention period, use the Volume Retention directive (see above).
We highly recommend against using this directive, because it is sure that some day, Bacula will recycle a Volume that contains current data. The default is no.
- File Retention = <time-period-specification>
- The File Retention directive defines the length of time that Bacula will keep File records in the Catalog database after the End time of the Job corresponding to the File records.
This directive takes precedence over Client directives of the same name. For example, you can decide to increase Retention times for Archive or OffSite Pool.
Note, this affects only records in the catalog database. It does not affect your archive backups.
For more information see Client documentation about FileRetention
- Job Retention = <time-period-specification>
-
The Job Retention directive defines the length of time that Bacula will keep Job records in the Catalog database after the Job End time. As with the other retention periods, this affects only records in the catalog and not data in your archive backup.
This directive takes precedence over Client directives of the same name. For example, you can decide to increase Retention times for Archive or OffSite Pool.
For more information see Client side documentation JobRetention
- Cleaning Prefix = <string>
- This directive defines a prefix string, which if it matches the beginning of a Volume name during labeling of a Volume, the Volume will be defined with the VolStatus set to Cleaning and thus Bacula will never attempt to use this tape. This is primarily for use with autochangers that accept barcodes where the convention is that barcodes beginning with CLN are treated as cleaning tapes.
- Label Format = <format>
- This directive specifies the format of the labels contained in this pool. The format directive is used as a sort of template to create new Volume names during automatic Volume labeling.
The <format> should be specified in double quotes, and consists of letters, numbers and the special characters hyphen (-), underscore (_), colon (:), and period (.), which are the legal characters for a Volume name. The <format> should be enclosed in double quotes (").
In addition, the format may contain a number of variable expansion characters which will be expanded by a complex algorithm allowing you to create Volume names of many different formats. In all cases, the expansion process must resolve to the set of characters noted above that are legal Volume names. Generally, these variable expansion characters begin with a dollar sign ($) or a left bracket ([). If you specify variable expansion characters, you should always enclose the format with double quote characters ("). For more details on variable expansion, please see the Variable Expansion chapter of the Bacula Enterprise Miscellaneous guide.
If no variable expansion characters are found in the string, the Volume name will be formed from the <format> string appended with the a unique number that increases. If you do not remove volumes from the pool, this number should be the number of volumes plus one, but this is not guaranteed. The unique number will be edited as four digits with leading zeros. For example, with a Label Format = "File-", the first volumes will be named File-0001, File-0002, ...
With the exception of Job specific variables, you can test your LabelFormat by using the var command in the Bacula Enterprise Console manual.
Label Format="${Level}_${Type}_${Client}_${Year}-${Month:p/2/0/r}-${Day:p/2/0/r}"Once defined, the name of the volume cannot be changed. When the volume is recycled, the volume can be used by an other Job at an other time, and possibly from an other Pool. In the example above, the volume defined with such name is probably not supposed to be recycled or reused.
In almost all cases, you should enclose the format specification (part after the equal sign) in double quotes.
In order for a Pool to be used during a Backup Job, the Pool must have at least one Volume associated with it. Volumes are created for a Pool using the label or the add commands in the Bacula bconsole program. In addition to adding Volumes to the Pool (i.e. putting the Volume names in the Catalog database), the physical Volume must be labeled with a valid Bacula software volume label before Bacula will accept the Volume. This will be automatically done if you use the label command. Bacula can automatically label Volumes if instructed to do so, but this feature is not yet fully implemented.
The following is an example of a valid Pool resource definition:
Pool {
Name = Default
Pool Type = Backup
}
The Scratch Pool
In general, you can give your Pools any name you wish, but there is one important restriction: the Pool named Scratch, if it exists behaves like a scratch pool of Volumes in that when Bacula needs a new Volume for writing and it cannot find one, it will look in the Scratch pool, and if it finds an available Volume, it will move it out of the Scratch pool into the Pool currently being used by the job.The Catalog Resource
The Catalog Resource defines what catalog to use for the current job. Currently, Bacula can only handle a single database server (MySQL, PostgreSQL) that is defined when configuring Bacula. However, there may be as many Catalogs (databases) defined as you wish. For example, you may want each Client to have its own Catalog database, or you may want backup jobs to use one database and verify or restore jobs to use another database.
Since both MySQL and PostgreSQL are networked databases, they may reside either on the same machine as the Director or on a different machine on the network. See below for more details.
- Catalog
- Start of the Catalog resource. At least one Catalog resource must be defined.
- Name = <name>
- The name of the Catalog. No necessary relation to the database server name. This name will be specified in the Client resource directive indicating that all catalog data for that Client is maintained in this Catalog. This directive is required.
- password = <password>
- This specifies the password to use when logging into the database. This directive is required.
- DB Name = <name>
- This specifies the name of the database. If you use multiple catalogs (databases), you specify which one here. If you are using an external database server rather than the internal one, you must specify a name that is known to the server (i.e. you explicitly created the Bacula tables using this name. This directive is required.
- user = <user>
- This specifies what user name to use to log into the database. This directive is required.
- DB Socket = <socket-name>
- This is the name of a socket to use on the local host to connect to the database. This directive is used only by MySQL. Normally, if neither DB Socket or DB Address are specified, MySQL will use the default socket. If the DB Socket is specified, the MySQL server must reside on the same machine as the Director.
- DB Address = <address>
- This is the host address of the database server. Normally, you would specify this instead of DB Socket if the database server is on another machine. In that case, you will also specify DB Port. This directive is used only by MySQL and PostgreSQL. This directive is optional.
- DB Port = <port>
- This defines the port to be used in conjunction with DB Address to access the database if it is on another machine. This directive is used only by MySQL and PostgreSQL. This directive is optional.
The following is an example of a valid Catalog resource definition:
Catalog
{
Name = MySQL
dbname = bacula;
user = bacula;
password = "" # no password = no security
}
or for a Catalog on another machine:
Catalog
{
Name = MySQL
dbname = bacula
user = bacula
password = ""
DB Address = remote.acme.com
DB Port = 1234
}
The Messages Resource
For the details of the Messages Resource, please see the Messages Resource Chapter of this manual.
The Console Resource
As of Bacula version 1.33 and higher, there are three different kinds of consoles, which the administrator or user can use to interact with the Director. These three kinds of consoles comprise three different security levels.
- The first console type is an anonymous or default console, which has full privileges. There is no console resource necessary for this type since the password is specified in the Director's resource and consequently such consoles do not have a name as defined on a Name = directive. This is the kind of console that was initially implemented in versions prior to 1.33 and remains valid. Typically you would use it only for administrators.
- The second type of console, and new to version 1.33 and higher is a “named” console defined within a Console resource in both the Director's configuration file and in the Console's configuration file. Both the names and the passwords in these two entries must match much as is the case for Client programs.
This second type of console begins with absolutely no privileges except those explicitly specified in the Director's Console resource. Thus you can have multiple Consoles with different names and passwords, sort of like multiple users, each with different privileges. As a default, these consoles can do absolutely nothing - no commands whatsoever. You give them privileges or rather access to commands and resources by specifying access control lists in the Director's Console resource. The ACLs are specified by a directive followed by a list of access names. Examples of this are shown below.
- The third type of console is similar to the above mentioned one in that it requires a Console resource definition in both the Director and the Console. In addition, if the console name, provided on the Name = directive, is the same as a Client name, that console is permitted to use the SetIP command to change the Address directive in the Director's client resource to the IP address of the Console. This permits portables or other machines using DHCP (non-fixed IP addresses) to “notify” the Director of their current IP address.
The Console resource is optional and need not be specified. The following directives are permitted within the Director's configuration resource:
- Name = <name>
- The name of the console. This name must match the name specified in the Console's configuration resource (much as is the case with Client definitions).
- Password = <password>
- Specifies the password that must be supplied for a named Bacula Console to be authorized. The same password must appear in the Console resource of the Console configuration file. For added security, the password is never actually passed across the network but rather a challenge response hash code created with the password. This directive is required. If you have either /dev/random or bc on your machine, Bacula will generate a random password during the configuration process, otherwise it will be left blank.
The password is plain text. It is not generated through any special process. However, it is preferable for security reasons to choose random text.
- AuthenticationPlugin = <plugin-definition>
-
Specifies the a plugin to use the authentication API framework which allows to configure a different set of authentication mechanisms (user credentials verification) using a dedicated Director plugins. It is called BPAM (Bacula Pluggable Authentication Modules). The first plugin available is a LDAP connector that is suitable to connect OpenLDAP or ActiveDirectory.
The new framework support standard user/password and MFA authentication schemes which are fully driven by external plugins. On the client side bconsole when noticied will perform user interaction to collect required credentials. Bacula will still support all previous authentication schemas including CRAM-MD5 and TLS. You can even configure TLS Authentication together with new BPAM authentication raising required security level. BPAM authentication is available for named Console resources only.
To use this feature you have to load dedicated Director plugin from directory pointed by Plugin Directory Director resource configuration. This plugin should be listed in director status command. Then you should configure the Console resource to use this plugin for authentication with the Authentication Plugin directive together with a named Console configuration in bconsole.conf as described in Console Configuration chapter of this manual.
Console { Name = "ldapconsole" Password = "xxx" Authentication Plugin = "ldap:<parameters>" }where parameters are the space separated list of one or more plugin parameters:
- url
- - LDAP Directory service location, i.e. "url=ldap://10.0.0.1/"
- binddn
- - DN used to connect to LDAP Directory service to perform required query
- bindpass
- - DN password used to connect to LDAP Directory service to perform required query
- query
- - a query performed on LDAP Directory serice to find user for authentication. The query string is composed as <basedn>/<filter>. Where `<basedn> is a DN search starting point and <filter> is a standard LDAP search object filter which support dynamic string substitution: %u will be replaced by credential's username and %p by credential's password, i.e. query=dc=bacula,dc=com/(cn=%u).
- starttls
- - instruct BPAM LDAP Plugin to use StartTLS extension if LDAP Directory service will support it and follback to no TLS if this extension is not available.
- starttlsforce
- - does the same what `starttls` but resport error on fallback.
The working configuration examples:
bacula-dir.conf - Console resource configuration for BPAM LDAP Plugin with OpenLDAP authentication example.Console { Name = "bacula_ldap_console" Password = "xxx" # New directive (on a single line) Authentication Plugin = "ldap:url=ldap://ldapsrv/ binddn=cn=root,dc=bacula,dc=com bindpass=secret query=dc=bacula,dc=com/(cn=%u) starttls" ... }bacula-dir.conf - Console resource configuration for BPAM LDAP Plugin with Active Directory authentication example.
Console { Name = "bacula_ad_console" Password = "xxx" # New directive (on a single line) Authentication Plugin = "ldap:url=ldaps://ldapsrv/ binddn=cn=bacula,ou=Users,dc=bacula,dc=com bindpass=secret query=dc=bacula,dc=com/(&(objectCategory=person)(objectClass=user)(sAMAccountName=%u))" ... } - TLS Enable = <yes|no>
-
Enable TLS support. If TLS is not enabled, none of the other TLS directives have any effect. In other words, even if you set TLS Require = yes you need to have TLS enabled or TLS will not be used.
- TLS PSK Enable = <yes|no>
-
Enable or Disable automatic TLS PSK support. TLS PSK is enabled by default between all Bacula components. The Pre-Shared Key used between the programs is the Bacula password. If both TLS Enable and TLS PSK Enable are enabled, the system will use TLS certificates.
- TLS Require = <yes|no>
-
Require TLS or TLS-PSK encryption. This directive is ignored unless one of TLS Enable or TLS PSK Enable is set to yes. If TLS is not required while TLS or TLS-PSK are enabled, then the Bacula component will connect with other components either with or without TLS or TLS-PSK
If TLS or TLS-PSK is enabled and TLS is required, then the Bacula component will refuse any connection request that does not use TLS.
- TLS Authenticate = <yes|no>
- When TLS Authenticate is enabled, after doing the CRAM-MD5 authentication, Bacula will also do TLS authentication, then TLS encryption will be turned off, and the rest of the communication between the two Bacula components will be done without encryption. If TLS-PSK is used instead of the regular TLS, the encryption is turned off after the TLS-PSK authentication step.
If you want to encrypt communications data, use the normal TLS directives but do not turn on TLS Authenticate.
- TLS Certificate = <Filename>
- The full path and filename of a PEM encoded TLS certificate. It will be used as either a client or server certificate, depending on the connection direction. PEM stands for Privacy Enhanced Mail, but in this context refers to how the certificates are encoded. This format is used because PEM files are base64 encoded and hence ASCII text based rather than binary. They may also contain encrypted information.
This directive is required in a server context, but it may not be specified in a client context if TLS Verify Peer is set to no in the corresponding server context.
Example:
File Daemon configuration file (bacula-fd.conf), Director resource configuration has TLS Verify Peer = no:
Director { Name = bacula-dir Password = "password" Address = director.example.com # TLS configuration directives TLS Enable = yes TLS Require = yes TLS Verify Peer = no TLS CA Certificate File = /opt/bacula/ssl/certs/root_cert.pem TLS Certificate = /opt/bacula/ssl/certs/client1_cert.pem TLS Key = /opt/bacula/ssl/keys/client1_key.pem }Having TLS Verify Peer = no, means the File Daemon, server context, will not check Directorâs public certificate, client context. There is no need to specify TLS Certificate File neither TLS Key directives in the Client resource, director configuration file. We can have the below client configuration in bacula-dir.conf:
Client { Name = client1-fd Address = client1.example.com FDPort = 9102 Catalog = MyCatalog Password = "password" ... # TLS configuration directives TLS Enable = yes TLS Require = yes TLS CA Certificate File = /opt/bacula/ssl/certs/ca_client1_cert.pem } - TLS Key = <Filename>
- The full path and filename of a PEM encoded TLS private key. It must correspond to the TLS certificate.
- TLS Verify Peer = <yes|no>
- Verify peer certificate. Instructs server to request and verify the client's X.509 certificate. Any client certificate signed by a known-CA will be accepted. Additionally, the client's X509 certificate Common Name must meet the value of the Address directive. If the TLSAllowed CN onfiguration directive is used, the client's x509 certificate Common Name must also correspond to one of the CN specified in the TLS Allowed CN directive. This directive is valid only for a server and not in client context. The default is yes.
- TLS Allowed CN = <string list>
- Common name attribute of allowed peer certificates. This directive is valid for a server and in a client context. If this directive is specified, the peer certificate will be verified against this list. In the case this directive is configured on a server side, the allowed CN list will not be checked if TLS Verify Peer is set to no (TLS Verify Peer is yes by default). This can be used to ensure that only the CN-approved component may connect. This directive may be specified more than once.
In the case this directive is configured in a server side, the allowed CN list will only be checked if TLS Verify Peer = yes (default). For example, in bacula-fd.conf, Director resource definition:
Director { Name = bacula-dir Password = "password" Address = director.example.com # TLS configuration directives TLS Enable = yes TLS Require = yes # if TLS Verify Peer = no, then TLS Allowed CN will not be checked. TLS Verify Peer = yes TLS Allowed CN = director.example.com TLS CA Certificate File = /opt/bacula/ssl/certs/root_cert.pem TLS Certificate = /opt/bacula/ssl/certs/client1_cert.pem TLS Key = /opt/bacula/ssl/keys/client1_key.pem }In the case this directive is configured in a client side, the allowed CN list will always be checked.
Client { Name = client1-fd Address = client1.example.com FDPort = 9102 Catalog = MyCatalog Password = "password" ... # TLS configuration directives TLS Enable = yes TLS Require = yes # the Allowed CN will be checked for this client by director # the client's certificate Common Name must match any of # the values of the Allowed CN list TLS Allowed CN = client1.example.com TLS CA Certificate File = /opt/bacula/ssl/certs/ca_client1_cert.pem TLS Certificate = /opt/bacula/ssl/certs/director_cert.pem TLS Key = /opt/bacula/ssl/keys/director_key.pem }If the client doesnât provide a certificate with a Common Name that meets any value in the TLS Allowed CN list, an error message will be issued:
16-Nov 17:30 bacula-dir JobId 0: Fatal error: bnet.c:273 TLS certificate verification failed. Peer certificate did not match a required commonName 16-Nov 17:30 bacula-dir JobId 0: Fatal error: TLS negotiation failed with FD at "192.168.100.2:9102".
- TLS CA Certificate File = <Filename>
- The full path and filename specifying a PEM encoded TLS CA certificate(s). Multiple certificates are permitted in the file. One of TLS CA Certificate File or TLS CA Certificate Dir are required in a server context, unless TLS Verify Peer (see above) is set to no, and are always required in a client context.
- TLS CA Certificate Dir = <Directory>
- Full path to TLS CA certificate directory. In the current implementation, certificates must be stored PEM encoded with OpenSSL-compatible hashes, which is the subject name's hash and an extension of .0. One of TLS CA Certificate File or TLS CA Certificate Dir are required in a server context, unless TLS Verify Peer is set to no, and are always required in a client context.
- TLS DH File = <Directory>
- Path to PEM encoded Diffie-Hellman parameter file. If this directive is specified, DH key exchange will be used for the ephemeral keying, allowing for forward secrecy of communications. DH key exchange adds an additional level of security because the key used for encryption/decryption by the server and the client is computed on each end and thus is never passed over the network if Diffie-Hellman key exchange is used. Even if DH key exchange is not used, the encryption/decryption key is always passed encrypted. This directive is only valid within a server context.
To generate the parameter file, you may use openssl:
openssl dhparam -out dh4096.pem -5 4096
- JobACL = <name-list>
- This directive is used to specify a list of Job resource names that can be accessed by the console. Without this directive, the console cannot access any of the Director's Job resources. Multiple Job resource names may be specified by separating them with commas, and/or by specifying multiple JobACL directives. For example, the directive may be specified as:
JobACL = kernsave, "Backup client 1", "Backup client 2" JobACL = "RestoreFiles"With the above specification, the console can access the Director's resources for the four jobs named on the JobACL directives, but for no others.
- ClientACL = <name-list>
-
This directive is used to specify a list of Client resource names that can be accessed by the console.
- RestoreClientACL = <name-list>
-
This directive is used to specify a list of Client resource names that can be used by the console to restore files. The ClientAcl is not affected by the RestoreClientACL directive.
ClientAcl = localhost-fd # backup and restore RestoreClientAcl = test-fd # restore only BackupClientAcl = production-fd # backup only - BackupClientACL = <name-list>
-
This directive is used to specify a list of Client resource names that can be used by the console to backup files. The ClientAcl is not affected by the RestoreClientACL directive.
- DirectoryACL = <name-list>
-
This directive is used to specify a list of directories that can be accessed by a restore session. Without this directive, the console cannot restore any file. Multiple directories names may be specified by separating them with commas, and/or by specifying multiple DirectoryACL directives.
- UserIdACL = <name-list>
This directive is used to specify a list of UID/GID that can be accessed from a restore session. Without this directive, the console cannot restore any file. During the restore session, the Director will compute the restore list and will exclude files and directories that cannot be accessed. Bacula uses the LStat database field to retrieve st_mode, st_uid and st_gid information for each file and compare them with the UserIdACL elements. If a parent directory doesn't have a proper catalog entry, the access to this directory will be automatically granted.
UID/GID names are resolved with getpwnam() function within the Director. The User UID/GID mapping might be different from one system to an other.
Windows systems are not compatible with the UserIdACL feature. The use of UserIdACL = *all* is required to restore Windows systems from a restricted Console.
Multiple UID/GID names may be specified by separating them with commas, and/or by specifying multiple UserIdACL directives.
- StorageACL = <name-list>
- This directive is used to specify a list of Storage resource names that can be accessed by the console.
- ScheduleACL = <name-list>
- This directive is used to specify a list of Schedule resource names that can be accessed by the console.
- PoolACL = <name-list>
- This directive is used to specify a list of Pool resource names that can be accessed by the console.
- FileSetACL = <name-list>
- This directive is used to specify a list of FileSet resource names that can be accessed by the console.
- CatalogACL = <name-list>
- This directive is used to specify a list of Catalog resource names that can be accessed by the console.
- CommandACL = <name-list>
- This directive is used to specify a list of console commands that can be executed by the console.
- WhereACL = <string>
- This directive permits you to specify where a restricted console can restore files. If this directive is not specified, only the default restore location is permitted (normally /tmp/bacula-restores). If *all* is specified any path the user enters will be accepted (not very secure), any other value specified (there may be multiple WhereACL directives) will restrict the user to use that path. For example, on a Unix system, if you specify “/”, the file will be restored to the original location. This directive is untested.
Aside from Director resource names and console command names, the special keyword *all* can be specified in any of the above access control lists. When this keyword is present, any resource or command name (which ever is appropriate) will be accepted. For an example configuration file, please see the Console Configuration chapter of this manual.
Please note the *all* keyword must be used alone in an ACL list. The following definition will be interpreted as a "Glob Pattern" for any FileSet including the "all" string:
FileSetACL = fs-test*, *all*
or
FileSetACL = fs-test* FileSetACL = *all*
All ACL Resource directives (JobACL, ClientACL, FileSetACL, ...) can accept “Glob Patterns” such as *.prod or `job.client1.* to ease the configuration.
ClientAcl = test-*
JobACL = job-test-*
FileSetACL = fs-test*
The Counter Resource
The Counter Resource defines a counter variable that can be accessed by variable expansion used for creating Volume labels with the LabelFormat directive. See the LabelFormat directive in this chapter for more details.
- Counter
- Start of the Counter resource. Counter directives are optional.
- Name = <name>
- The name of the Counter. This is the name you will use in the variable expansion to reference the counter value.
- Minimum = <integer>
- This specifies the minimum value that the counter can have. It also becomes the default. If not supplied, zero is assumed.
- Maximum = <integer>
- This is the maximum value value that the counter can have. If not specified or set to zero, the counter can have a maximum value of 2,147,483,648 (2 to the 31 power). When the counter is incremented past this value, it is reset to the Minimum.
- *WrapCounter = <counter-name>
- If this value is specified, when the counter is incremented past the maximum and thus reset to the minimum, the counter specified on the WrapCounter is incremented. (This is not currently implemented).
- Catalog = <catalog-name>
- If this directive is specified, the counter and its values will be saved in the specified catalog. If this directive is not present, the counter will be redefined each time that Bacula is started.
The Statistics Resource
The Statistics Resource defines the statistic collector function that can send information to a Graphite instance, to a CSV file or to bconsole with the statistics command (See (here) for more information).
- Statistics
- Start of the Statistics resource. Statistics directives are optional.
- Name = <name>
- The Statistics directive name is used by the system administrator. This directive is required.
- Description = <string>
-
The text field contains a description of the Statistics that will be displayed in the graphical user interface. This directive is optional.
- Interval = <time-interval>
-
The Intervall directive instructs the Statistics thread how long it should sleep between every collection iteration. This directive is optional and the default value is 300 seconds.
- Type = <CSV|Graphite>
-
The Type directive specifies the Statistics backend, which may be one of the following: CSV or Graphite. This directive is required.
CSV is a simple file level backend which saves all required metrics with the following format to the file: “<time>, <metric>, <value>\n”
Where <time> is a standard Unix time (a number of seconds from 1/01/1970) with local timezone as returned by a system call time(), <metric> is a Bacula metric string and <value> is a metric value which could be in numeric format (int/float) or a string True or False for boolean variable. The CSV backend requires the File = parameter.
Graphite is a network backend which will send all required metrics to a Graphite server. The Graphite backend requires the Host = and Port = directives to be set.
If the Graphite server is not available, the metrics are automatically spooled in the working directory. When the server can be reached again, spooled metrics are despooled automatically and the spooling function is suspended.
- Metrics = <metricspec>
-
The Metrics directive allow metric filtering and <metricspec> is a filter which enables to use * and ? characters to match the required metric name in the same way as found in shell wildcard resolution. You can exclude filtered metric with ! prefix. You can define any number of filters for a single Statistics. Metrics filter is executed in order as found in configuration. This directive is optional and if not used all available metrics will be saved by this statistics backend.
Example:
# Include all metric starting with "bacula.jobs" Metrics = "bacula.jobs.*" # Exclude any metric starting with "bacula.jobs" Metrics = "!bacula.jobs.*"
- Prefix = <string>
-
The Prefix allows to alter the metrics name saved by statistics to distinguish between different installations or daemons. The prefix string will be added to metric name as: “<prefix>.<metric_name>” This directive is optional.
- File = <filename>
-
The File is used by the CSV statistics backend and point to the full path and filename of the file where metrics will be saved. With the CSV type, the File directive is required. The statistics thread must have the permissions to write to the selected file or create a new file if the file doesn't exist. If statistics is unable to write to the file or create a new one then the collection terminates and an error message will be generated. The file is only open during the dump and is closed otherwise. Statistics file rotation could be executed by a mv shell command.
- Host = <hostname>
-
The Host directive is used for Graphite backend and specify the hostname or the IP address of the Graphite server. When the directive Type is set to Graphite, the Host directive is required.
- Host = <number>
-
The Port directive is used for Graphite backend and specify the TCP port number of the Graphite server. When the directive Type is set to Graphite, the Port directive is required.
Console Multi-Factor Authentication Plugins
Time-based One-Time Password (TOTP) Authentication Plugin
The TOTP Authentication Plugin is compatible with the RFC 6238. Many smartphone apps are available to store the keys and compute the TOTP code.
Console {
Name = "totpconsole"
Password = "xxx"
Authentication Plugin = "totp:<parameters>"
}
where parameters are the space separated list of one or more plugin parameters:
- keydir
- - The directory where the TOTP keys are stored. /opt/bacula/etc/conf.d/totp by default.
- no_qrcode
- - Do not generate QR code at the first connection. The Bacula administrator must provide the TOTP key to users manually using the btotp command for example.
- sendcommand
- - Use the command specified by sendcommand to send the QRCode as a PNG image to the user.
The working configuration examples:
bacula-dir.conf - Console resource configuration for BPAM TOTP Plugin example.
# In bacula-dir.conf
Console {
Name = "totpconsole"
Password = "xxx"
# New directive
Authentication Plugin = "totp"
}
# in bconsole.conf
Console {
Name = totpconsole
Password = "xxx" # Same as in bacula-dir.conf/Console
}
Director {
Name = mydir-dir
Address = localhost
Password = notused
}
At the first console connection, if the TLS link is correctly setup (using the shared secret key), the plugin will generate a specific random key for the console and display a QR code in the console output. The user must then scan the QR code with his smartphone using an app such as Google Authenticator or Aegis (Opensource).
The program qrencode (![]() 4.0) is used to convert the otpauth URL to a QR code.
4.0) is used to convert the otpauth URL to a QR code.
The btotp command can be used to manipulate TOTP keys. For example, to generate the QR code in the terminal:
# /opt/bacula/bin/btotp -n totpconsole -q
To generate the otpauth URL in the terminal (can be used to generate a QRcode later) with qrencode:
# /opt/bacula/bin/btotp -n totpconsole -u otpauth://totp/Bacula:totpconsole?secret=OR2TM22...&issuer=Bacula
In this example, the QR code is sent by email to the console owner:
# In bacula-dir.conf
Console {
Name = "roberto"
Password = "xxx"
# New directive
Authentication Plugin = "totp: sendcommand=\"mpack -s 'Bacula Console Access for %d' -d /opt/bacula/etc/template %a %c@acme.org\"\""
}
# in bconsole.conf
Console {
Name = roberto
Password = "xxx" # Same as in bacula-dir.conf/Console
}
Director {
Name = mydir-dir
Address = localhost
Password = notused
}
At the first console connection, the plugin will generate a specific random key for the console and send a QR code PNG file via the command configured. In the example, the mail command mpack will send an email with the attachement to the email “roberto@acme.org”
Subject: Bacula Console Access for mydirector-dir Please find the QR Code needed to access the Bacula director ---image attached---
The following variables can be used in the sendcommand string:
- %a
- - Path to the QR code png file
- %d
- - Director name
- %c
- - Console name
LDAP Authentication Plugin
A LDAP Authentication Plugin that is suitable to connect OpenLDAP or ActiveDirectory connector plugins is available.
Console {
Name = "ldapconsole"
Password = "xxx"
Authentication Plugin = "ldap:<parameters>"
}
where parameters are the space separated list of one or more plugin parameters:
- url
- - LDAP Directory service location, i.e. "url=ldap://10.0.0.1/"
- binddn
- - DN used to connect to LDAP Directory service to perform required query
- bindpass
- - DN password used to connect to LDAP Directory service to perform required query
- query
- - a query performed on LDAP Directory serice to find user for authentication. The query string is composed as <basedn>/<filter>. Where `<basedn> is a DN search starting point and <filter> is a standard LDAP search object filter which support dynamic string substitution: %u will be replaced by credential's username and %p by credential's password, i.e. query=dc=bacula,dc=com/(cn=%u).
- starttls
- - instruct BPAM LDAP Plugin to use StartTLS extension if LDAP Directory service will support it and follback to no TLS if this extension is not available.
- starttlsforce
- - does the same what `starttls` but resport error on fallback.
The working configuration examples:
bacula-dir.conf - Console resource configuration for BPAM LDAP Plugin with OpenLDAP authentication example.
Console {
Name = "bacula_ldap_console"
Password = "xxx"
# New directive (on a single line)
Authentication Plugin = "ldap:url=ldap://ldapsrv/
binddn=cn=root,dc=bacula,dc=com bindpass=secret
query=dc=bacula,dc=com/(cn=%u) starttls"
...
}
bacula-dir.conf - Console resource configuration for BPAM LDAP Plugin with Active Directory authentication example.
Console {
Name = "bacula_ad_console"
Password = "xxx"
# New directive (on a single line)
Authentication Plugin = "ldap:url=ldaps://ldapsrv/
binddn=cn=bacula,ou=Users,dc=bacula,dc=com bindpass=secret
query=dc=bacula,dc=com/(&(objectCategory=person)(objectClass=user)(sAMAccountName=%u))"
...
}
Example Director Configuration File
An example Director configuration file might be the following:
#
# Default Bacula Director Configuration file
#
# The only thing that MUST be changed is to add one or more
# file or directory names in the Include directive of the
# FileSet resource.
#
# For Bacula release 1.15 (5 March 2002) -- redhat
#
# You might also want to change the default email address
# from root to your address. See the "mail" and "operator"
# directives in the Messages resource.
#
Director { # define myself
Name = rufus-dir
QueryFile = "/home/kern/bacula/bin/query.sql"
WorkingDirectory = "/home/kern/bacula/bin/working"
PidDirectory = "/home/kern/bacula/bin/working"
Password = "XkSfzu/Cf/wX4L8Zh4G4/yhCbpLcz3YVdmVoQvU3EyF/"
}
# Define the backup Job
Job {
Name = "NightlySave"
Type = Backup
Level = Incremental # default
Client=rufus-fd
FileSet="Full Set"
Schedule = "WeeklyCycle"
Storage = DLTDrive
Messages = Standard
Pool = Default
}
Job {
Name = "Restore"
Type = Restore
Client=rufus-fd
FileSet="Full Set"
Where = /tmp/bacula-restores
Storage = DLTDrive
Messages = Standard
Pool = Default
}
# List of files to be backed up
FileSet {
Name = "Full Set"
Include {
Options { signature=SHA1}
#
# Put your list of files here, one per line or include an
# external list with:
#
# @file-name
#
# Note: / backs up everything
File = /
}
Exclude {}
}
# When to do the backups
Schedule {
Name = "WeeklyCycle"
Run = level=Full sun at 2:05
Run = level=Incremental mon-sat at 2:05
}
# Client (File Services) to backup
Client {
Name = rufus-fd
Address = rufus
Catalog = MyCatalog
Password = "MQk6lVinz4GG2hdIZk1dsKE/LxMZGo6znMHiD7t7vzF+"
File Retention = 60d # sixty day file retention
Job Retention = 1y # 1 year Job retention
AutoPrune = yes # Auto apply retention periods
}
# Definition of DLT tape storage device
Storage {
Name = DLTDrive
Address = rufus
Password = "jMeWZvfikUHvt3kzKVVPpQ0ccmV6emPnF2cPYFdhLApQ"
Device = "HP DLT 80" # same as Device in Storage daemon
Media Type = DLT8000 # same as MediaType in Storage daemon
}
# Definition for a DLT autochanger device
Storage {
Name = Autochanger
Address = rufus
Password = "jMeWZvfikUHvt3kzKVVPpQ0ccmV6emPnF2cPYFdhLApQ"
Device = "Autochanger" # same as Device in Storage daemon
Media Type = DLT-8000 # Different from DLTDrive
Autochanger = yes
}
# Definition of DDS tape storage device
Storage {
Name = SDT-10000
Address = rufus
Password = "jMeWZvfikUHvt3kzKVVPpQ0ccmV6emPnF2cPYFdhLApQ"
Device = SDT-10000 # same as Device in Storage daemon
Media Type = DDS-4 # same as MediaType in Storage daemon
}
# Definition of 8mm tape storage device
Storage {
Name = "8mmDrive"
Address = rufus
Password = "jMeWZvfikUHvt3kzKVVPpQ0ccmV6emPnF2cPYFdhLApQ"
Device = "Exabyte 8mm"
MediaType = "8mm"
}
# Definition of file storage device
Storage {
Name = File
Address = rufus
Password = "jMeWZvfikUHvt3kzKVVPpQ0ccmV6emPnF2cPYFdhLApQ"
Device = FileStorage
Media Type = File
}
# Generic catalog service
Catalog {
Name = MyCatalog
dbname = bacula; user = bacula; password = ""
}
# Reasonable message delivery -- send most everything to
# the email address and to the console
Messages {
Name = Standard
mail = root@localhost = all, !skipped, !terminate
operator = root@localhost = mount
console = all, !skipped, !saved
}
# Default pool definition
Pool {
Name = Default
Pool Type = Backup
AutoPrune = yes
Recycle = yes
}
#
# Restricted console used by tray-monitor to get the status of the director
#
Console {
Name = Monitor
Password = "GN0uRo7PTUmlMbqrJ2Gr1p0fk0HQJTxwnFyE4WSST3MWZseR"
CommandACL = status, .status
}